项目背景与摘要
甲骨文作为中国已知最早的成熟文字系统,承载着极其重要的历史与语言学研究价值。然而,现有的数字化甲骨文数据集大多局限于孤立切分的字符切片,极度缺乏对于全面文本解读至关重要的上下文和宏观结构化信息。
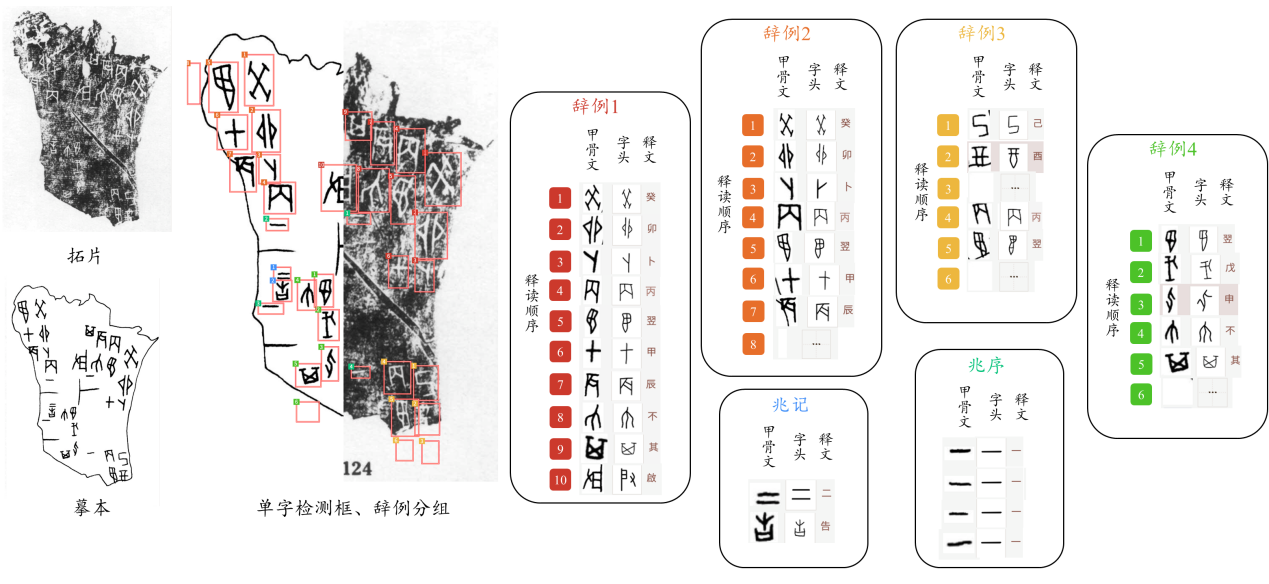
为了攻克这一瓶颈,研究团队推出了甲骨文多模态数据集 (OBIMD)。这是一个大规模、公开可用的综合学术语料库,不仅包含像素级完美对齐的拓片与重绘摹本图像,还集成了极其详尽的字符级边界框定位、类别标签以及带有阅读序列的句子级释文。通过将视觉空间特征、文字结构模态和句法语义高度对齐整合,OBIMD 为利用先进人工智能对古文字进行可扩展、系统化的分析与破译奠定了坚实的科学基础。
数据集核心意义
传统的单字检测或分类模型(如 Oracle-MNIST)隐含假设一个字符的身份可以仅凭其局部视觉表现完成恢复。但在真实的破译场景中,大量甲骨字形模糊、风化残损或因骨片碎裂而残缺不全,即使最顶尖的古文字学家也无法仅凭一个局部切片做出判定。学者往往需要联合参考拓片的上下文环境、对应摹本的清晰线条走向以及已知的语法释文推论来确立正确的识读假设。OBIMD 的提出正顺应了这一复合科学诉求。
高粒度数据规模统计
OBIMD 数据集全面覆盖了商代五个历史时期的丰富铭文样本,具体高精度参数如下表:
在核心的句子/成分分组中,还特别细化标注了 4,192 个非句法语素元素,包括 3,785 个兆序 (OracleSequence)(代表占卜的顺序)以及 407 个兆辞 (OracleOutcome)(表明占卜的最终结果)。
三大数据模态定义
- 拓片图像 (Rubbings):基础的物理文本模态,系统性地源自“殷契文渊”数字资料库。包含从最为权威的《甲骨文合集》中随机成比例抽样的 9,913 幅标本,以及为了补充破碎度而专门引入的 164 幅出自《小屯南地甲骨/花园庄东地甲骨》的高完整度拓片。
- 数字摹本 (Facsimiles):用于专家提取字形线条及非专家精准定位目标的关键视觉媒介。为了确保与原拓片像素级别的绝对精准对齐,图像由学者参照《甲骨文摹本大系》进行全人工无缝红线重绘,剔除了原书中夹杂的与非文字盾纹干扰,避免机器误判。
- 参考释文 (Reference Transcriptions):提供了常规且具备句子阅读顺序的现代中文字形对照扫描版面,作为还原复杂非线性排版阅读序列的客观物理证据。
三阶段协同标注与验证流程
面对甲骨文解析极度依赖高级古文字学专家(稀缺资源)的现实痛点,项目组设计了一套高效、可扩展的多层级人机协同工作流:
数据获取与标准化 (Data Acquisition)
全面汇聚并清洗来自“殷契文渊”的原始多模态素材,进行图像统一索引、基准注册以及摹本重绘对齐。
智能自动化预标注 (Pre-annotation)
该阶段旨在提供精密的视觉候选区辅助。系统首先利用基于 YOLO 的目标检测网络在拓片和摹本上分别提取出所有潜在字符候选框;随后依托匈牙利算法结合空间及视觉特征相似度计算出最优跨模态映射网络;最后通过字形数据库的形状检索输出 Top-k 类别推荐候选和多层级异体字关联标签。这一步成功减轻了人工近 80% 的初期圈定任务。
多层级专家群组审校 (Collaborative Verification)
定义了三种清晰的角色分工,实现效率与严谨性的完美闭环:
- 非专家人员 (Non-specialist):在 Web 便捷终端上,利用智能平台的三视图同步对照、拖拽排列、以及手写/Top-10 字形推荐进行初始框校对、句子划分及标记不确定性,工作效率狂飙达 60 倍。
- 研究生群体 (Graduate):由接受过系统甲骨文与计算机双重训练的研究生担任,全面复审非专家提交的结果,并纠正由于文字学基础不足带来的认知偏差。
- 顶级专家仲裁 (Expert):顶层专家仅对研究生历经多轮迭代和参考书目求证后仍标注为“高争议/高不确定”的极少数难例行使终审一票否决和更正权力。
甲骨文字形分类体系:字头、子字头与异体字
为了精准应对甲骨文高度复杂的多样性和演变,OBIMD 数据集中的分类标签(Label / SubLabel)深度参考了 Oracular Digital Platform 设计的三级字形层级概念,具体定义如下:
- 字头 (Graph):甲骨文字的基本单位,相当于一个单独的甲骨文文字概念(在部分学术著作中称为“字位”)。字头是一个集合,囊括了所有具有相同或高度相似的字形、语言用法或语义含义的字符与异体字。
- 子字头 (Subgraph):字头之下的次级分类单位。设立子字头的目的是为了在同一字头下,更好地区分那些具有不同书写风格或部件组成的字形。例如,甲骨文中的复合字可能因部件组合或空间位置的不同而产生巨大的外观差异(如“疾”字的诸多不同写法),独体字也可能因增减部分笔画而不同。子字头概念的引入,能够将“外观不同但用法和含义相同”的字形准确归类,这既提升了字符和文本检索的精确度,也能灵活适应未来甲骨文破译研究带来的分类细化或整合需求。
- 异体字 (Variant):子字头之下的最基础单位,即我们在出土甲骨拓片上实际看到的、真实的字形书写示例。异体字的存在构成了建立字头或子字头的实体依据。将真实的字形实例直接挂载于相应的字头/子字头之下,不仅有利于在子字头级别进行持续的分类与归档,更能有效解决以往由于手工描摹失误、遗漏收录或重复导致的一系列学术分类错误问题。
精细化三级分层标注模式
OBIMD 包含的格式化 JSON 条目(共计 10,077 条)采用了高度解耦且有严密父子关联的“图像-句子-字符”三层结构体系:
| 字段名称 | 类型 | 核心功能与文字学语义解析 | 示例数据 |
|---|---|---|---|
| Facsimile / Rubbing | String | 保存完美对齐的对应模态完整底层图像存储路径 | /rubbing/h00002.jpg |
| GroupCategory | String | 确定特定文本簇的分类(如:InscriptionSentence1, OracleSequence, OracleOutcome, Uncertain) | InscriptionSentence1 |
| Position | String | 精确的定位检测框,格式采用严格的 (x, y, width, height) 像素坐标系 | 558, 581, 80, 218 |
| OrderNumber | Integer | 规定该字符框在当前所属句子组合内部的绝对识读先后序列次序(从0开始) | 5 |
| Label / SubLabel | String | 对应前面提到的“字头-子字头”映射。Label 对应主字符字头的 UID,SubLabel 精准追踪由于书写风格、时代演变产生的特定子字头(异体结构)变体编码 | xkubtjk815 |
| SeatFont | Integer | 缺失/占位标记开关。若原石断裂但语法必须包含某字则置为 1(生成无文字图像的纯空间位置框),正常可见字为 0 | 0 |
| Mark | Integer | 异常标志。-1 正常;0 字形严重损坏不可辨;1 学界无共识争议字;2 仅拓片可见存疑;3 仅摹本出现 | -1 |
任务一:高精度字符联合检测与识别 (基于 YOLOv11)
实验以 9:1 的比例根据甲骨碎片 ID 划分训练集和验证集(排除占位符标签),模型运行至 200 个 Epoch 后取得的详尽基准跑分数据如下表所示:
| 评测基准子任务 (Subtask) | mAP@50 | mAP@50:95 | Precision (精确率) | Recall (召回率) | F1 Score | Average IoU |
|---|---|---|---|---|---|---|
| 摹本 - 主字符 (Facsimile Main) | 0.6700 | 0.4470 | 0.6473 | 0.6134 | 0.6395 | 0.7560 |
| 摹本 - 子变体字 (Facsimile Sub) | 0.5853 | 0.3904 | 0.6148 | 0.5245 | 0.5630 | 0.7564 |
| 拓片 - 主字符 (Rubbing Main) | 0.5141 | 0.3045 | 0.6386 | 0.4271 | 0.5118 | 0.7214 |
| 拓片 - 子变体字 (Rubbing Sub) | 0.4284 | 0.2563 | 0.5627 | 0.3739 | 0.4493 | 0.7118 |
定量分析:数据表明,摹本主字符取得了最优的表现,而原始拓片的子字形匹配难度最高。这深刻反映出底层原始材质侵蚀对特征提取网络的巨大挑战,证明了 OBIMD 为古籍脚本图像识别提供了一个具有深度区分度的学术基准。
任务二:句子级字符智能聚类与阅读重组测试
为了探究高级的句法和排列逻辑,团队设置了“句子字符聚类”与“基于 Transformer 的乱序字符重新排序”两项极具古文字学应用价值的探索任务:
A. 字符属于同一句子群组的监督聚类表现
| 评测子项 | AMI (调整互信息) | NMI (归一化互信息) | ARI (调整兰德系数) | Purity (纯度得分) |
|---|---|---|---|---|
| 主字符系统 (Main Characters) | 0.54 | 0.60 | 0.53 | 0.84 |
| 子变体系统 (Sub-characters) | 0.51 | 0.53 | 0.50 | 0.79 |
高纯度 (Purity=0.84) 表明预测划分在同一个簇中的字符具有极强的一致性,但较低的互信息暗示当面对极为稠密或物理交错的版面排列时,句子边缘检测边界依旧是个难点。
B. 打乱顺序句子的阅读次序完全恢复率 (Transformer Position Classifier)
| 评测子项 | Top-1 准确率 | Top-3 准确率 | ADE (平均物理位置距离误差) |
|---|---|---|---|
| 主字符序列重组 | 75.35% | 91.57% | 0.4974 |
| 子字形序列重组 | 72.78% | 90.35% | 0.5260 |
实验证明该数据集在不依赖 Unicode 传统预训练语言模型的硬性限制下(通过位置分类机制),仍能驱动网络实现高效的非线性识读路径推演。
基于匈牙利算法的跨模态框匹配技术
在 OBIMD 数据集的智能预标注体系中,一个核心技术突破就是设计了能够跨越“拓片图像(高噪声、风化严重)”与“纯重绘摹本图像”的字符边界框关联匹配机制。其本质是为两种视觉模态中各自产生的 YOLO 检测框集合,通过寻找全局最优解完成“一对一”完美对齐映射。
算法的核心公式在于构建匹配代价矩阵 (Cost Matrix),每一个交点元素的代价得分计算不仅衡量拓片检测框与摹本检测框之间的归一化相对几何空间质心距离 (Normalized Spatial Distance),更融入了通过深度骨干网络提取的字形内部纹理笔画走向视觉相似度特征 (Visual Similarity Score)。最后由匈牙利算法动态求解,使整个配对网络的全局综合代价值最小化。
💡 跨模态智能匹配与匈牙利算法仿真模拟器
调节下方两个核心考量指标的控制权重,实时观察系统生成的全局代价矩阵(数值代表不匹配成本)以及匈牙利算法求解出的最终绿色高亮最优跨模态字符对齐方案: