
转自《数字人文》“古籍智能”系列专题
古籍印刷用字的整理与规范
王立军(北京师范大学文学院)
古籍数字化和汉字编码都是信息时代非常关键的工作,既各自独立,又相互关联。二者都涉及汉字的规范问题,尤其是古籍印刷字形的整理与规范问题。
在对古籍用字进行汉字编码,或是制作古籍字库的过程中,我们都要面临的一个问题,就是如何看待汉字发展过程中所积累下来的复杂字形?如何去选择?采取什么样的标准?要回答这些问题,需要从以下四个方面来分析:汉字规范的必要性,汉字规范简史,古籍印刷用字字形认同原则,以及古籍印刷用字字形选取原则。
(一)汉字规范的必要性
汉字历史悠久,汉字的特点决定了其形体一定是非常复杂的。从甲骨文算起,汉字已经有了三四千年的历史,实际上其起源的时间应该更早。作为一种表意文字,汉字的形体往往是对客观事物的反映。客观事物复杂多样,汉字的字形也一定复杂多样。在早期造字的时候,汉字多采用象形的方法,这种类型的汉字形体往往是对客观事物轮廓的描摹,客观事物是什么样,就会画成什么样。但对于一些更为复杂的事物,没有办法直接把它描绘出来,这时候主要是采取“因义构形”的方式,也就是根据它的意义去构建其形体。比如“保”字,古人是按照“背小孩”的形象去描绘的(图1左),因为最早的时候“保”具有教育、教养、养育等含义。所以《周礼》记载的保氏,相当于当时的教育官员。教育小孩跟现在保姆带小孩其实有相通之处,所以“保”现在可以用于“保姆”一词。这说明古时“保”字是根据它的意义来造的。再比如折断的“折”,它的意思怎么用字形表现?我们知道,先有词,然后才造字。先有折断,然后才去造“折”字。那究竟应该怎么去造这个字?因义构形就是根据意义去构造它的形体。折断,顾名思义,是把什么东西给弄断了。所以古人造字的时候,就选取了一个部件“斤”,也就是斧头,然后左边画了一棵中间不相连的草,用这种方式表示折断的意义。另一种写法是在左边的草中间,特意加上两横,表示这里是断开的,突出强调折断的意思。这两种写法,都是根据“折”的意义去构建其形体结构的(图1右)。


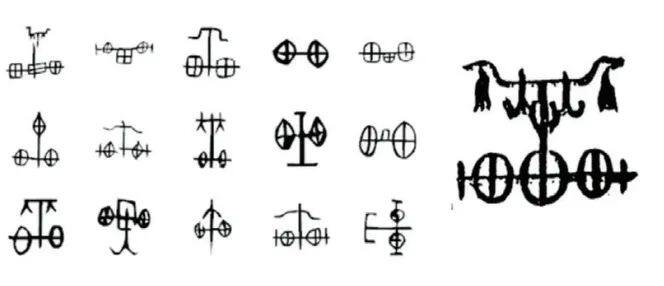
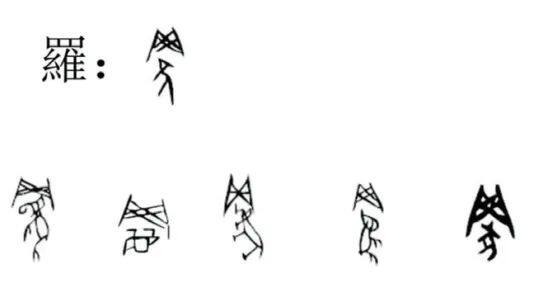
因义构形,往往会导致一个字有多种不同的写法,像牙齿的“齿”字(图2),在甲骨文中就有多种写法,“嘴”里的“牙齿”从一颗到六颗的都有,这些都是“齿”字。当时没有规范的理念,所以这几种写法都可以使用。甲骨文的“車”字也是这样,我们可以看到形形色色的“車”(图3),有简单的,有复杂的:从仅仅画两个轮子、一个车轴的“車”字,到车厢、车辕、车盖以及架马的车轭也都画出来。金文的“車”就更形象了。这说明,汉字作为表意文字,其形体必然非常复杂。再比如“罗”,就是我们现在所说的天罗地网的“罗”,繁体字作“羅”。甲骨文字形上边画的是一个网,下边是一个鸟,很显然,它是用捕鸟的场景来体现罗网的“罗”的意义(图4)。而且“罗”字在甲骨文里不只一种写法。我们可以看到有的画的是捕大象、捕鹿、捕老虎、捕兔子、捕野猪等,捕什么就画成什么,这样就造出了多种不同字形的“罗”字。
在甲骨文中一个字有多种不同的写法是允许存在的,但是随着汉字的数量越来越多,这种现象的存在就成了累赘,成了障碍。一代一代地累积下来,汉字的数量和体系就越来越庞杂。在《汉语大字典》里“国”字就收了20个字形(图5)。这20个“国”都是从不同的角度去造的,我们现在传承下来的简化字“国”的写法,就是国中有玉;第二种写法是国中有王;第三种写法是国中有民,也就是说国家当中不仅有王,而且也应该有民;国家还有疆土,四面八方的疆土,所以国中有八土、国中有八方,都可以表达“国”的意思。“国”的繁体字作“國”,其最早的写法实际上是“或”,左边的“囗”表示国家的疆域,上下两横表示疆界,右边的“戈”表示用武器包围边疆。后来由于“或”被借去表示代词等用法,为表示其本义“国家”便又在外面增加了一个“囗”,写作“國”;而疆域的意义则在左边添加一个土字旁,写作“域”。从中可以看到汉字在发展过程中的复杂现象,以及它们相互之间的纠葛。本来是一个字,后来可以繁衍出多个字。这些字在有些时代用法是相同的,但是到后代用法又开始相互区别,所以这些现象都给我们整理汉字带来非常大的麻烦。

一方面,汉字发展的历史和汉字自身特点决定了汉字是非常复杂的。另一方面,传承的古籍数量众多,古籍当中实际应用的汉字纷繁复杂,而且有关古籍用字的标准又不统一。截至2022年5月份,一直没有关于古籍用字即繁体字的规范标准,只是在有些标准中部分涉及到繁体字。如《简化字总表》,有简化字对应的繁体字字形;如《第一批异体字整理表》,实际上是基于繁体字的字形进行整理的,所以会涉及到繁体字。但有时候这些规范标准给予某个繁体字的地位是不一样的。例如“宝”字在《简化字总表》里推荐的相应繁体字形是“寶”,但是在《第一批异体字整理表》推荐的相应繁体字形是“寳”,而把《简化字总表》推荐的“寶”放在括号里(做备选)。《第一批异体字整理表》是用于整理异体字的,一旦赋予某个字形异体字的身份,这个字形就不能再作为规范字形使用了。因此按照《简化字总表》, “宝”的繁体字“寶”是推荐字形,但是按照《第一批异体字整理表》这个字形放在括号中,它就被弃用了。可见相关标准对于繁体字的处理有时是不一致的,这就有必要对已有的标准进行调整。例如“寳”和“寶”,如果从统一的角度来讲,就需要把《第一批异体字整理表》当中的正异关系颠倒过来。
还有一种问题,就是新旧字形造成的混乱,新旧字形是由于受后来的一些汉字整理规则的影响,对一些字形做了新的改造。如走之旁、录字旁、吴字旁等偏旁都进行了统一的新化处理,这样就会造成新字形与古籍用字之间的冲突。因为新字形不一定在古籍中出现过,就使得所谓的新字形和旧字形之间形成了对立。如果执行标准不统一,就会导致混乱,新中有旧,旧中有新,进一步加深了汉字的复杂程度。
国际编码字符集编制的用意是好的,但是由于这项工作某些原则的不完善,导致了一些新的混乱现象。目前我们只能说国际编码字符集是一个编码字表,而不能说它是古籍印刷的规范字表。因为它指向的目标不一样,操作的原则不一样,由此生成的结果也不一样,所以不能直接拿国际编码字符集作为我们整理古籍用字的规范标准。其主要问题包括:字符集是中日韩字形并存的;认同不彻底,异写字重复编码;简繁并存,不适合直接用来整理古籍;一方面编码字符集数量非常庞大,有很多生僻字,另一方面,面向应用的字量又是不够的。而且,即使在中国内部的不同地区,所使用的繁体字的字形也不统一,如“黄”字在大陆、台湾和香港的字形都不一样(图6)。


另一个复杂的问题是,现行字库的字形在笔形变异规则的处理方面存在不统一现象。比如“琴”“瑟”“琵”“琶”几字中左上角的玉字旁,或者俗称王字旁,应该像“玨”“班”“理”一样,在左边的偏旁末笔要变提,但在“琴”“瑟”“琵”“琶”字形中没有遵守这样的规则。为什么没有遵守规则,是没有理由而言的,这是典型的字形变异规则内部不统一的表现。再比如“辱”“唇”“蜃”上面都是“辰”,但“辱”和“唇”“蜃”各部件的结构关系、位置关系却是不一样的。而且同样是“辱”,单独成字的时候和在“蓐”“褥”“薅”字形中做偏旁的时候,部件的结构关系、位置关系也是不一样的。这是历史原因造成的,在整理汉字的时候没有从系统性的规则去考虑,就导致一些矛盾现象日积月累遗留下来。
而且,不同的字库之间的字形处理也不一样,华文楷体和方正楷体在一些局部细节上的处理就不一样。像监督的“督”,部件“小”中间一笔是竖还是竖钩,方正楷体和华文楷体的字库处理是不一致的。“遴”字在昆仑楷体和方正楷体里,右上角部件的末笔处理为点,还是捺,也是不一致的。
即使同一字库,内部规则也有不一致的地方。如“㡀”做部件时,右下角到底是横折钩还是横折?图7中上面一组是带钩的,下面一组是不带钩的,这两组之间有什么区别?没有任何理由可以解释。规则就是可解释性,如果不具有可解释性,那它就不能成为规则。
宋体和楷体之间存在的差异,也是一个“老大难”的问题。如图8中字形,左边是楷体,右边是宋体。其中一些笔画,比如左边部件“舟”中间的一笔,楷体显示为提,宋体则显示为横。这些现象增加了汉字字形的复杂程度。无论是在历史上还是在现实应用过程中,汉字的歧异程度、复杂程度,都是极高的。因此,汉字规范是汉字自身的必然要求。
(二)汉字规范简史
汉字发展的历史,也是汉字不断整理规范的历史。根据文献记载,最早的“书同文”出现在东周时期,在《礼记·中庸》就记载:“今天下车同轨,书同文,行同伦。”[1]周朝时天下一统,因此可以实现文字的统一,但甲骨文基本上处于自然发展的状态。西周金文则明显是经过整理的,其规范程度远高于甲骨文,其异体字相比甲骨文少得多。
到秦始皇时期,由于此前经历过文字异形、言语异声、车途异轨的战国时代,所以秦始皇统一天下,首先做的工作就是书同文,因为没有统一的文字,政令就无法在全国颁行。当时诸侯各国文字的歧异程度是非常严重的,同样一个字在秦国和赵国的简繁程度差异很大。所以“秦始皇帝初兼天下,丞相李斯乃奏同之,罢其不与秦文合者”,[2]用当时的秦文字统一了六国文字。
汉朝也特别强调文字的重要性。汉代文字学家许慎在《说文解字·叙》中说:“盖文字者,经艺之本,王政之始,前人所以垂后,后人所以识古。”[3]他把文字的社会作用提高到一个前所未有的高度。汉代同样也非常重视文字的规范,而且把文字的规范与否作为考核官员的重要标准之一。《汉书·艺文志》:“吏民上书,字或不正,辄举劾。”[4]如果官员的文书或奏折当中用了不规范字,那官位可能就不保了。可见当时对文字规范的重视程度。
唐代也非常重视汉字的规范工作。无论是官方还是文人阶层,都在这方面做了大量的工作。颜元孙的《干禄字书》,曾被奉为唐代“字样学”的经典之作。什么是字样?就是在众多的异体字中提供的一个最标准的样式。当时规定“进士考试,理宜必尊正体”,要参加正式的官方的考试,必须使用《干禄字书》推荐的正字。《干禄字书》把当时一个字的不同写法分为三类,即俗、通、正。俗是民间俗用;通则是就通行层面而言,即相对正式但在非最正式场合亦可采用;而在最正式的场合,一定用正字。这样正、通、俗形成了用字规范的三个层级。《干禄字书》的目的是什么?字书是字典,干禄就是求官,所以这个字典就相当于“求官宝典”。求官宝典所写的就是哪个字规范,哪个字不规范。由此可见,规范字是当时人们求官的秘诀和重要武器。
新中国成立之后,也很快开展了汉字整理工作。当时汉字整理工作有三项重要任务:一是整理异体字,成果即《第一批异体字整理表》;二是简化汉字,因为汉字繁体字形过于复杂,所以要进行简化;三是推行汉语拼音方案。
1965年出台了《印刷通用汉字字形表》。当时的印刷字形与现在的电脑字库不同,而是刻铅字。由于不同的印刷厂依据来源不同,所刻的铅字字形也就不一样。同样一本书,不同厂家印制的字形就会有差异。这太让人头疼了,当时引起了非常广泛的讨论。各印刷厂所印书籍中不同字形的复杂歧异程度,确实让人觉得到了不规范不可的地步。当时国家非常重视,组织专家研制《印刷通用汉字字形表》,统一铅字字形。这个标准规范了6,196个汉字的字形样式,是对印刷宋体字的一次大规模统一整理。为了简化字形和方便书写,整理过程中对部分字形和部件形体进行了改造,形成了所谓的新字形。1986年,国家又发布了《现代汉语通用字表》,字形规则沿用《印刷通用汉字字形表》,字量增加到7,000。
2013年,国家又颁布了《通用规范汉字表》,收字量扩展到8,105,字形规则沿用《印刷通用汉字字形表》。其基本的结构分三个层级,一级字表共3,500字,收录最常用汉字;二级字表共3,000字,收录次常用汉字。一级字表和二级字表共同构成了基本通用字集,共6,500字。此外还有三级字表,所收的主要是专用字,如姓氏、人名、地名、科学技术术语等特殊领域的用字,总共1,605字,是对基本通用字集的有效补充,所以可以叫做补充通用字集。
上述几个规范字表都是面向简体字的,一直没有面向古籍整理专门的规范标准。随着国家对优秀传统文化的重视,古籍数字化与印刷出版工作步伐日益加快,其用字量远远超过现代汉语通用文本的范围,且多数需要采用历史通行的繁体字系统,亟需一个与《通用规范汉字表》相配套的古籍印刷用字的规范字形表。
在国家语言文字工作委员会的组织下,经过多年的研制,2021年10月,国家市场监督管理总局和国家标准化委员会发布了《古籍印刷通用字规范字形表》,并于2022年5月正式生效。这是我国第一个关于古籍印刷字形的规范标准。这个标准规定了古籍印刷通用字收字和宋体字形规范原则,给出了14,250个古籍印刷通用字的字形、字音以及在国际编码字符集ISO/IEC 10646中的码位,适用于传世古籍的印刷出版,以及现代书刊的繁体版印刷。这个字表的研制是新中国成立以来对传世古籍印刷字的第一次整理规范工作,意义非常重大。
(三)古籍印刷用字字形认同原则
古籍印刷字形的认同与计算机编码字形的认同之间是有差异的。计算机编码赋予某一字形的地位或性质,不一定适用于古籍印刷字形规范领域。例如,“户”字的三个字形、“散”字的四个字形,分别被赋予了不同的计算机编码(图9),但在古籍整理领域,并不需要赋予它们相同的地位,即使“户”和“散”的不同字形都保留,也是将其放在不同的层级。因此,古籍整理和计算机编码对待字形歧异的态度及处理原则是不同的。

古籍整理过程中,字形认同的标准是分层级的。我们把它分成三个层级:一是普及类古籍,采取最大可能认同。因为普及类古籍是面向大众的,让大众去认读一个字的各种不同写法是没有必要的,这对大众而言是非常重的负担,会严重影响古籍的普及度。二是文化类古籍,其异写字应该全部认同,有价值的异构字可以适当保留。三是小学类古籍,应该最大限度地存真,因为这类古籍字形是有研究价值的。所以在古籍整理过程中,面向不同层面的古籍、不同的目标人群,我们对待异写字的态度是不同的。
在对汉字的不同形体进行认同时,可将其内部差异分为6级:1级差异是最小级别的差异,这些字的差异仅仅表现在笔画层面上(图10-1)。2级差异是部件位置的差异,如是左右结构,还是包含结构、上下结构等,这种差异仅仅表现在部件的位置布局上,部件类型和部件形体都没有变,只是摆放的相对位置关系有差别(图10-2)。3级差异是部件形体发生了变化(图10-3)。4级差异是部件形体发生混同,变成跟其他的部件形体一样了(图10-4)。5级差异是部件形体增减,部件的数量发生了变化,这种情况的变异更加严重,但是还没有到构意发生改变的层面(图10-5)。6级差异是整字构意发生了改变。异体字内部又分作两大类,一类是异写字,一类是异构字。异构字之间有构意差别,异写只是写法有差别。前5级差异都属于异写层面,第6级差异则属于异构层面。例如,“玉”字旁的“玩”字,代表“把玩”——玉器属于宝物,人们很喜欢,就经常放在手里把玩;另一个字形“翫”,为“習”字旁,造字的角度就改变了。“玩”的“玉”字旁表示把玩的对象是玉,为什么把玩玉?因为人们特别喜欢,不忍心把它放下,就形成了一种习惯,引申为习性、习俗。这就使得“玩”和“翫”的构造意图发生改变,理解其意义的角度也发生改变。这种变化较大,因此把它放在第6级(图10-6)。






这些不同层级的差异,处理时需要采取不同的策略。不同的目的决定我们的认同规则细分到什么程度,认同到哪一级。形体的差异层级实际上相当于规范宽严的不同层级。
(四)古籍印刷用字字形选取原则
古籍印刷用字主形选择的总体原则有六:首先是系统性原则,即同一个部件处于同一个位置时,写法应尽量相同。第二是流通性原则,应重视两个流通度,一是古代的流通度,即在古籍中出现的字频相对较高。二是当今古籍印刷实际应用中的流通度。《通用规范汉字表》简化字对应的繁体字和传承字已改用了新字形,但在古籍中的用字是不考虑新字形的,也即我们现在对古籍用字的整理没有新旧字形的概念,不受新旧字形的束缚。但是新字形在印刷过程中使用多年,人们已经习惯,只要这个字形在古籍中确曾使用,而且与古籍用字系统不矛盾,那也应该优先选择。第三是理据性原则。在满足上述两个条件的情况下,应尽量照顾传统理据。因为汉字是表意文字,非常重视理据。《说文解字》与《康熙字典》中的字形,应优先考虑。第四是简约性原则。在满足前三个条件的情况下,还应考虑字形是否简约,是否更方便书写。第五个原则是应当充分考虑两岸交流需要,尽量缩小两岸传承字形之间的差异。在大陆、台湾及香港,同一繁体字,也存在着一些差异,在优选字形的时候尽量追求最大公约数。最后一个原则是在依顺序采用以上条件优选字形时,还需要考虑个别字与其周边字形的区别度,尽量避免同形字与形近字的增多,尽量减少混淆。
主形选取当中的操作细则包括:一是选择以往古籍印刷中通行度较高的字形。优先选择古籍中和现在都使用的高频字形,既适应现代人认读,又不失古书原意,这其实是对上述总原则的具体落实。例如,“並”和“竝”两个形体在简化字系统中都已经成为“并”的异体字,不再使用。但在古籍印刷中,“並”的字频远高于“竝”,则选“並”不选“竝”。再如“真”和“眞”两字形,“眞”在古籍用字中尚属高频,但在现代用字中已不使用;“真”既是古籍高频字,现代也一直沿用,则选“真”不选“眞”。二是选择字理明晰或变异度较小的古籍常用字形,以承袭传统,便于学习。例如,“強”和“强”选前者,因为“強”从“弘”,更能突显字理。三是在选择近现代已定型的隶变、楷化字和构字量较高的楷体部件时,以尊重汉字自然发展规律和现代使用习惯为原则。四是选择符合书写规律和布局便宜的字形,因为现代汉字在书写过程中要考虑到书写的便利。所谓书写规律,就是合乎书写的生理习惯。我们现在的习惯书写顺序是从上到下、从左到右,这是一种自然的书写方向,所以尽量不出现反向书写的笔画。如“内”和“內”,一个是按照“人”形书写,一个是按照“入”形书写,我们认为按照“人”形书写更符合运笔流畅的标准,因此选择前者。五是参考古代专书考据的结论,修改被否定的错字。例如,一字的多种字形都较为常见,但是其中有的字形是由书写错误造成的,以讹传讹,导致错误写法和正确写法并行。我们如果能够弄清楚哪个字形是错的,哪个字形是对的,则选择正确的那个。“昏”的两种字形早就存在,但是段玉裁考证认为“昬”实际上是错的,因此选择时还是要回归正确字形。六是保持音义相同的部件在不同字中形体一致性的同时,还要充分尊重汉字自然发展的结果,已经稳定的变异部件不再改动。虽然需要纠正一些错误,但是有些字的变异已成为既定事实,这种情况应尽量尊重现实,如果硬要改造已成定局的写法,会对大家的应用造成很大冲击。比如“册”和“冊”,单独成字或做部件时,我们一般会选择“册”,如“删”“姗”“珊”“栅”等。但是,像“扁”“典”等字形很早就存在了,应不再改动,保持原形。七是楷化字由于各种原因出现部件趋同现象,或近似部件混同现象,需区别对待。由于长时间的部件错讹,使得音义完全不同的两个部件形体长期混淆,这种混淆多是成批的,而字理又很清晰,因此对其进行区分是有必要的。例如,争议较多的“壬”和“
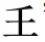
”,二者的系统性是非常强的,对其进行区分有利于汉字的学习,所以我们主张这两个部件应当区分。但是有些部件的变异大部分趋向一致,只有少部分另做处理,这也是在汉字长期演变过程中出现的一些另类现象,而且久已定型,对此我们仍保持其原型,不再强制改动。例如,部件“攴”在现在多数字形中变成了反文旁“攵”,但在个别字形中仍写作“攴”,如“敲”。对于这些沿袭已久的例外写法也不能非要强求统一,而要尊重既成的事实。
总之,我们整理古籍过程中对字形的处理,应当既符合古代典籍的实际情况,又要照顾到现实应用,尽量做到纵向沟通和横向沟通。所谓纵向沟通,就是古今沟通;所谓横向沟通,就是海峡两岸暨香港、澳门的沟通。要做到这两个沟通兼顾,充分考虑现代古籍阅读者识别与理解古籍字形的实际情况,力求做到既科学规范,又方便阅读。
汉字编码与古籍数字化平台建构
王晓明(教育部语言文字应用研究所)
汉字信息处理,对使用者来说,最主要的是汉字信息的存储、交换、输入、输出。信息存储与交换的核心基础是编码,信息的输入与输出呈现同样与编码息息相关。
(一)编码
编码,就是用预先规定的方法编成的代码,将信息从一种形式或格式转换为另一种形式,转换后的形式更便于使用者(机器或人)处理和运用。在中文信息领域,编码有两种指代,一种是指字符的计算机系统底层编码,即字符在虚拟空间的码位,作为计算机的内部处理码,用于信息处理和交换等,也就是编码字符集中的编码,如,区位码、交换码、内码等;另一种是指字符的应用层编码,它用于字符的检索和输入等,即通常所说的检字法或输入法编码,如五笔字型、四角号码等,俗称外码。
编码是汉字进入计算机的先决条件。汉字能够进入计算机,并且被正常运用、进行有效的信息处理,取决于多方因素,但最基础的要素有三个:一是这个汉字要有一个底层编码,有了编码这个字在计算机内才有位置,计算机才能对其进行处理;二是要有字库的支撑,有了字库这个字才能被显示、打印输出;三是要有输入法,有了输入法才能方便地从计算机中将这个字调取使用。比如,我们书写文章,就要通过输入法才能将写作内容输入计算机。输入法的编码是与汉字的自然属性相关的,它便于人们记忆和使用。
编码的本质是信息形式或格式的转换。由此可见,计算机处理文字,它的直接处理对象并非文字本身,而是其编码。即便是字库和输入法,也都是要和这个编码来衔接的。字库要将该字的字形数据信息与其编码相关联,输入法要将输入法编码和计算机底层编码相关联,计算机就是这样处理汉字的。
(二)编码字符集
编码字符集指的是一组无歧义的规则,用以建立一个字符集和该字符集中的字符及其编码表示之间的对应关系。通俗的讲,它是多个字符的集合,这些字符按一定顺序排列,且其中每个字符均有唯一的编码,字符与编码之间一一对应。
目前,涉及汉字的编码字符集有多个,如GB 2312、GBK、BIG5、GB 18030、GB 13000、ISO 10646以及Unicode等。那么,这些编码字符集之间是什么关系呢?
GB 2312是最早在中国大陆境内的计算机系统里使用的编码字符集,当时国内所有汉字系统都是以这个编码字符集为基础的,并一直沿用至今。BIG5是中国台湾地区计算机系统所使用的编码字符集,它是一个工业标准。后来,我国为Windows95/98系统制定了GBK(规范)。GB 2312、GBK与BIG5分别是国家和地区的区域性编码字符集。随着网络时代的兴起,便制定了国际编码字符集。制定编码字符集的原则是:在哪个范围内进行信息交换,就制定哪个范围的编码字符集。比如,在单位内部交换,可以制定单位内部的编码字符集;在国家内部交换,就制定国家编码字符集;在国际范围内交换,就要制定国际编码字符集。ISO/IEC 10646就是国际编码字符集。
GBK是什么?它与ISO/IEC 10646有关。国际编码字符集ISO/IEC 10646:1993,其CJK基本集,也就是大家通常所说的大字符集,包含20,902个汉字,GB 2312和BIG5的汉字均包含其中。标准正式出版之后,中国为了能与国际标准衔接,首先让计算机在字量层面实现20,902个汉字,便制定了一个国家规范GBK。GBK是以GB 2312为核心进行扩展,实现机制与GB 2312相同。GBK是一个规范,不是强制性国家标准,后来在应用过程中存在没有被严格遵守的情况,引起了一些信息传递的错误。因此,在2000年便将这个规范上升为国家标准,并对体系结构进行了整体规划,即GB 18030-2000。GB 18030逐版升级,后来有了2005年版,最新版本是2022年版,它的收字内容全部来自ISO/IEC 10646,只是编码和体系结构不同。
Unicode又是什么?它是英文Universal Code的缩略语,顾名思义,就是统一编码。然而,现在这个术语具有多重含义。最初,它是由美国的一些大企业组成的联盟集团,此后,世界各国陆续有企业加入,我国也有很多公司加入了这个联盟。它们从工业界的角度认为文字需要统一编码,应该制定一个标准,便将该工业标准命名为Unicode,这个工作是与国际标准ISO/IEC 10646并行的,并且编码字符也是一致的,只不过ISO/IEC 10646侧重于编码本身,而Unicode更侧重于技术实现。同时,Unicode也是对国际标准ISO/IEC 10646编码的一种称谓。
GB 13000是什么?GB 13000就是我们国家等同采用国际标准ISO/IEC 10646的国内标准号,二者内容是完全一致的。
另外,从事数字化工作,还需特别关注的编码字符集是GB/T 12345,通常也称之为辅一集,它相当于GB 2312的繁体字符集。原来的计算机内存很小,计算机系统也受实现技术的限制,不可能同时将简体字和繁体字同放在一个平台上。为了解决繁体字的信息处理问题,后来就研制了一个对应的繁体字符集,该字符集总体上与GB 2312是一一对应的。你可能会问,GB 2312是6,763字,为什么GB/T 12345有6,800多字?这是因为,汉字的简繁存在一对多的情形,所以就多出了几十字。一对多的处理主要考虑了当时的字频情况,哪个字的字频高,就直接将其安排在对应的码位上,将另外的对应字追加到字表后部。
例如,图1a红框内的这些字,上半部为GB/T 12345的繁体字集,下半部是GB 2312简体字集,同为16区,繁简字编码都是一一对应的。图1b红框内的字是一对多的处理实例,因为“发展”的“發”比“头发”的“髮”频度高,所以相应的位置就放了“发展”的“發”,“髮”被追加到字表后部。


古籍数字化,有些内容是来自于二手数据,源自用于出版的排版数据,在这些排版数据中可能就会涉及到这个问题:在屏幕上输入的是简体字,一旦将显印字库置换为GB/T 12345的字库,内容便自动变为相应的繁体形式。在古籍数字化的过程中,如果是这种二手数据的话,需要对这种情况给予特别关注。所以说,GB/T 12345在方便信息简繁切换的同时,也给今天的数字化埋下了隐患。
(三)如何择定字集
计算机通用平台是为了日常信息交流而准备的,所以它执行的是现行文字规范标准。古籍用字是不在这个框架之内的,不受这个限制,古籍数字化需要自己来构建平台。因为规范都是向后规范,就是只能规范以后怎么做,不能规范以前怎么做。古籍是一种具有历史性的存在,如果现在要数字化,就要根据数字化的规范来构建平台,用现行的通用平台是不行的。
那应该如何选定字集呢?现在,我们的计算机系统普遍采用的都是国际标准ISO 10646。选定字集,需要考虑这几个因素:一是编码字符集的情况,二是计算机对编码字符集的实现情况,三是如何把我们要数字化的对象在计算机上实现,包括要数字化的内容用字的基本概况。这三个方面相结合,才能确定如何来择定字集。
首先,介绍一下国际标准ISO 10646中汉字部分的编码情况。国际标准编码的宗旨是要把世界上所有的文字都统一编码。国际标准构建的体系结构是四维的编码空间,首先将空间分成128个组,每一个组里有128个平面,每一个平面里有256行,每一行里有256个码位,这个编码空间大约有二十亿个码位,足够用了。这是国际上构建的一个体系结构。其中和中国相关的文字都在哪儿呢?在目前已编码的文字中,汉字在基本平面、第二辅助平面和第三辅助平面;我国的少数民族文字在基本平面和第一辅助平面,基本上就这四个平面与中国相关。整个标准,目前计算机系统支撑的情况是,开放了其00至10共17个平面(约100万个码位),并在0E平面规定了Ideographic Variation Sequence(简称IVS)。
汉字的编码情况是什么样的呢?目前,汉字编码是从CJK直至CJK_G,共8个集合。CJK和CJK_A约28,000字,在基本平面。CJK_B至CJK_F在第二辅助平面,CJK_G在第三辅助平面,CJK_H正在编码过程中。2020年公布的版本,是最新的标准版,其中汉字编码共有90,000多字。在具体实施过程中,这90,000多字如何选择呢?这就要看这些字集编了什么东西,是不是都是我们要用的,跟我们有什么关系?当初,CJK编码的时候,基本上把各个国家和地区现行的信息系统中已经实现的编码字符集都纳入其中,和中国相关的就是大陆的GB 2312,还有台湾的BIG5。此外,我们通过特殊论证,申请将《现代汉语通用字表》的7,000字也纳入其中,还有辅一集,我们也有计算机实现。所以中国的这些字集都在CJK里。但是,《简化字总表》有百十来字(包括类推简化字和对应的繁体字)没有在CJK的20,902个汉字里。至CJK_A,《简化字总表》已经收齐了,同时,我国还有两个字符集也收齐了,一个是辅三集,一个是辅五集,通常人们称其一为古籍用字,另一个称为罕用字,都是7,000多字。至此,我国当初的这些编码字符集/字表的汉字,都已收入国际标准。CJK和CJK_A编码完成之后,中国代表团主动整理了《汉语大字典》(第一版)还有《康熙字典》里没有收入到国际标准的那些字,这是CJK_B的核心基础。除了按照认同规则予以认同的字之外,这两个大部头字典里的字都收入到国际标准里了。从CJK_C开始,提交的字基本上都是各个国家和地区在数字化过程中发现的未编码字,没有一个统一原则,收字的标准尺度和适用性方面没有关系,哪个国家/地区发现了未编码字,就把它提交到国际标准里面进行编码。所以,这些字集都很零散,而且还包含一些古籍隶定字。
已完成的古籍文献数字化工程所采用的字集情况,可作为择定字集的参考。早在2000年,CJK_A编码标准公布之后,我们做了《文渊阁四库全书》电子版。因为小学类的字头用字非常多,根据测算,我们决定《四库全书》小学类字书的字头不单独造字,没有的话就以图片形式存在。经过工程实践,《四库全书》实际用字(不包括小学类字书字头)大概是29,000多字。后来,我们做《四部丛刊》也是用的同一个字集。所以,如果不包括小学类的话,用两万多字是没有问题的。再后来,我们开始规划“中华字库”工程,因为“中华字库”工程的目标是要把古籍文献里用到的每一个字符都提取出来,最后构建出版行业的一个标准字集。根据这一目标,我们进行规划,将国际标准已编码部分整体纳入其中。还要考虑到包括少数民族文字,17个开放平面(一百万个编码)全部都得用上。刚提到的IVS原本是用于解决已编码字的异体字形显现问题。在这里,我们借用这种技术,把它作为一个编码空间的扩充方案来运用。这是为了防止“中华字库”工程在实施过程中,万一编码字符超过一百万,还能确保有编码空间可扩充。所以说,我们择定字集要结合这三个方面,一是编码情况,二是计算机对编码字符集的支撑情况,三是结合我们自己数字化的对象和目标。
(四)如何确定字型
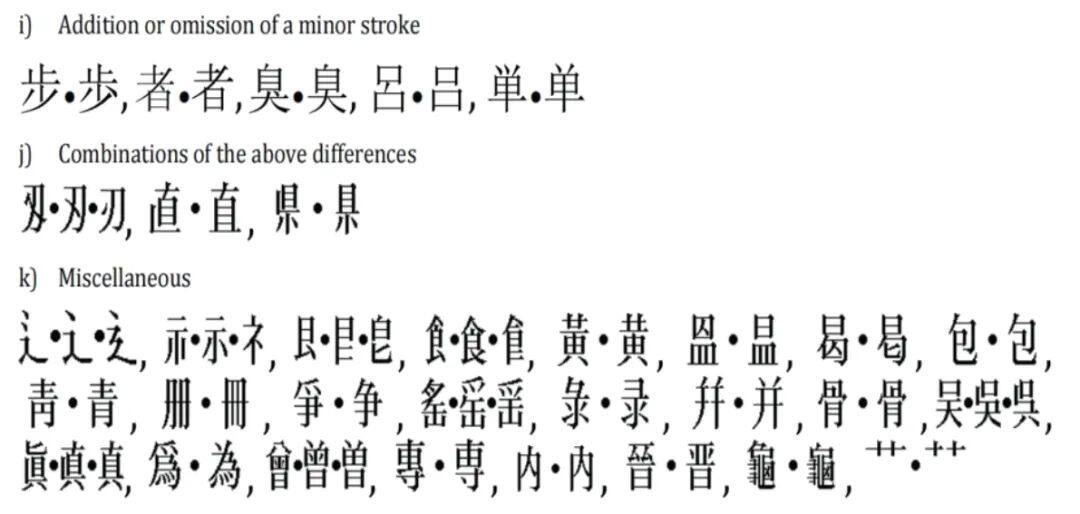
国际标准ISO/IEC 10646对字符的编码,是按照文种统一编码,而不是按照语言、国度或地域进行编码。所以在国际标准里,看不到“汉字”这个名称,它在国际标准里以CJK Unified Ideographs指称,意为CJK统一表意文字。汉字统一编码方案是由中国代表团提出的,理由是中日韩汉字同源、属于同一个文字体系;尽管形态有微小差异,但其抽象字形是相同的;另外,经过统计分析,中日韩汉字具有统计同一性,就是说,字形相同的汉字基本都是同源的。基于以上原则,对中日韩汉字进行统一编码。编码所遵循的认同规则,详见标准AnnexS,其中详细叙述了认同过程和认同规则。如图2所列各组字符都是可以认同的。从中不难看出,新旧字形基本上都是认同的,包括不同写法的草字头、不同写法的“吴”“骨”等字形,以及“者”“步”这些带或不带点的字形,都是认同的。
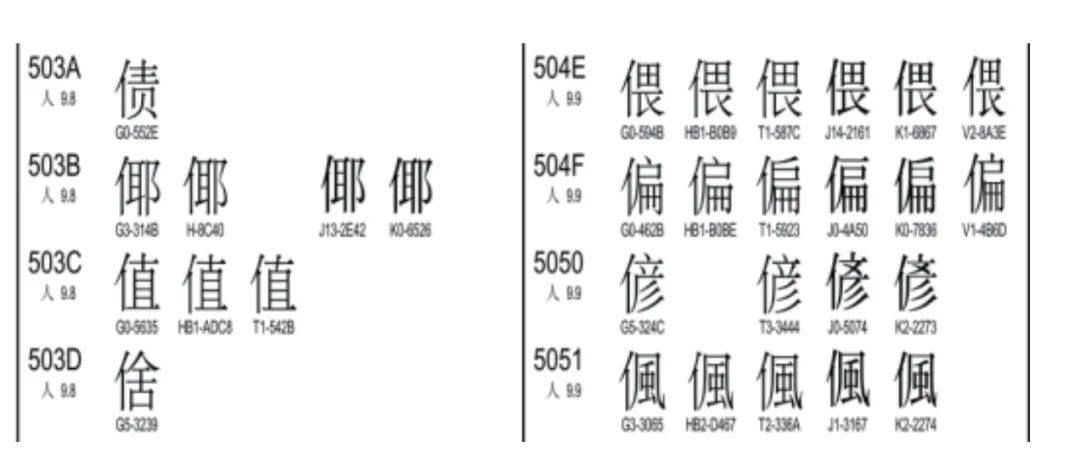
依据这个认同规则对汉字进行编码,最终形成了CJK国际编码字符集。编码字符集中,每一个编码后面均对应多列字形(如果有的话)。每个成员提交了该字,都会将其字形附于编码后的相应列位。如图3中的“偏”字,第一列是中国大陆的字形,第二列是中国香港的字形,第三列是中国台湾的字形,第四列是日本的字形,第五列是韩国的字形,最后一列是越南的字形,这些写法都是认同的。我们在做数字化平台构建时,在定型的过程中,这些字型选哪个都可以。只要符合认同规则,对应这个码位就是没有问题的。
需要注意的是,认同规则在个别地方与文字学概念存在差异。比如,前面讲的认同规则,原则上新旧字形都是认同的,但是“奂”“奐”不认同,理由是:相应构件结构不同,这与新旧字形的整理是存在差异的。此外,按认同规则,简繁不认同,正异也不认同。然而,“戶”“户”“戸”却分别编码。还有一些字,原本是同一个字,却给了多个编码,大家看着会很混乱。这就是编码字符集和汉字字表的不同。
汉字字表的面向对象是人,如果觉得其中哪个字不合适,将其删除即可。然而,编码字符集却不可如此操作。原因是,编码字符集面向的对象是机器,一旦编码确立,此后便会产生很多的电子数据,而编码隐藏在数据背后,人是不知道的。旧平台上的数据移植到新平台上,要照顾到前后衔接,即便原编码字存在问题也不可轻易删除,不然的话,原来的信息就传递不过来。所以,认同规则中就有了一个源代码分离原则,这条规则仅适用于CJK基本集编码之前已有的那些字符集,这些都是各个国家/地区已经在计算机系统中实现的字符集。在这些字符集里,如果同一成员对可认同汉字已分别编码,那在国际标准中也要分别各给一个码位。

图4中是源代码分离的例字。这些字按照认同规则,原本都应该认同,但是由于后面标出的成员字符集已经分别编码,标“T”的指中国台湾地区,标“G”的指中国大陆,所以,图中的每组字都没被认同。以“净(51C0)凈(51C8)”这组为例,大陆的GB 2312中编码了干净的“净”字,又在GB/T 12345里编码了“凈”。按照认同规则,这两个字本应认同,但是,由于中国大陆的字符集里已经给这两个字分别编码,那这两个字在国际标准中也都要存在。如果台湾地区或日本、韩国存在此类情况,都是这样处理。前面提到的3个“户”字,就是由于台湾地区的字符集里给它们分别编码,所以在国际标准里也给了三个编码。但是,如果是大陆有一个字,台湾地区有一个字的话,按照认同规则,该认同就得认同。
另外,大家注意一下这些例子,如,“壮(58EE)壯(58EF)”,这组按照认同规则原本是可以认同的,但是由于大陆的源代码分离,所以分别编码。好在已经分别编码,否则与我们的语言文字规范严重冲突,因为这两个字在《简化字总表》里是简繁对应关系,而简繁字是不能认同的。这也从另一个侧面说明源代码分离原则存在的必要性。上图4中都是一些涉及常用字的字例,虽然可以认同,但实际上已经分别编码,在实际应用中需留意。
大家在看标准,看字表时,会觉得非常乱,不好用。如果先把认同规则看明白,再返回去用这个字符集,就会觉得很清晰,而且之后也能够确保很好地把这些理念落实到字符集的应用中去,恰当、合理地确定字型。
数据加工通常都是操作员的工作,操作员的文字水平参差不齐,如何解决计算机里的文字与实际文献用字的差异问题呢?下面以《文渊阁四库全书》电子版的实际工程为例进行说明。
1990年代末,我们开始尝试解决这一问题。当时,工程生产线上有约300名操作员,为给操作员现场答疑解惑,配备了约60名语言文字相关专业的老师以及博士、硕士研究生。试验了一段时间发现,由于答疑不及时,拖慢了工程进度;由于多人的随机处理,标准掌控不一致,导致数据质量不佳。即便在数据加工过程中不断整理出一些认同字表,但在执行中因人而异,导致各方面的不统一。在这种情况下,我们及时调整工程策略,把整个平台的字符集进行了全面梳理。结合《文渊阁四库全书》的用字特点与字型特征,在认同规则框架内,整理出一套符合《文渊阁四库全书》整体风貌的字型库。《文渊阁四库全书》多半是手抄本,用字主体是楷体,我们做了楷体字库,这样就很贴近文献本身的用字实际,减少了很多工程上的麻烦。有了这个平台之后,我们在做《四部丛刊》电子版时,整个工程生产线上仅配备一名文字学硕士来处理疑难字,其职责不再是现场答疑,而是在后台处理数据加工过程中提取出来的疑难字。《文渊阁四库全书》是八亿字,《四部丛刊》是一亿字,疑难字处理人员却从60人降到了1人,其工作也不像以前那么繁重。
由此可见,科学定型对提升古籍数字化工程的进度和数据质量都有很大的促进作用。构建一个好的平台,在加快工程进度的同时,也确保了处理标准的统一,促进了数据质量的提升。
汉字编码和适于关联性汉字的编码方法
陆勤(香港理工大学计算学系)
(一)汉字编码与应用之间的关系
我们现在做的编码是对一个抽象符号的编码,而不是对字样来做编码。以英文为例,作为一种拼写文字,英文有一套固定的字符,包括字母和符号,比如a、b、c、d和标点符号。而每个字符都要分开编码。这是因为每一个字符在拼写中都有特定的意思,或者有其特定的功能,从而影响到意思。为什么p和m要分开编码?因为apple和ample的意思是不同的,这两个符号会使得这一串的文字的意思不同。对于每一种语言来说,其字符的编码要有唯一性。比如英文字母a的编码,是0041,而俄文的字母a的编码则是0410。可见编码和语言是有一定关系的。这两种语言里都用a,为什么要给它分开编码?因为计算机有它的功能。比如,如果找某个拉丁文字,可以通过它编码的区来找到这个文字,再如,汉字最早的编码区在GB2312里。所以怎么区分汉字、英文和俄文呢?就是通过它们的编码区来区分。不同语系字符需要区分是对它们功能性的要求,所以要分开编码。况且俄文有33个字母,而英文只有26个字母,不能混为一谈。如果有不同功能和不同意义,在编码上是要分开的,这也是为什么英文和俄文的字母集是分开编码的。
然而,同一个抽象符号可能有不同写法,比如英文的字母A会有不同的样子,比如

或者A。我们不会给同一个抽象符号的不同写法分开编码。因为如果给它们分开编码,那么它们两个的内码是不一样的。这样,当你生成文件时如果输入了

,而我查找该字符时输入了A,那我在你的文件里就找不到这个字母。虽然字形不同,如果要表达的都是同一个抽象符号,它们的编码必须相同的,这才是编码的本质:方便交流和查找。不同的字形在电脑里都用排版的字体信息来体现。当查找文字时,不需要理会字体信息,只需查找抽象字符的内码,这样对信息的交流和沟通非常方便。

汉字编码的难点是什么?以图1中骨头的“骨”字为例,海峡两岸和香港的写法各有笔画上的差异。“骨”上面部件中的横折,第一个字形是向左边,第二个字形是向右边(香港惯用的字形),第三个是台湾省惯用的字形,因为台湾承袭了骨头的部首是“肉月旁”,所以它的月字用了一点一提的字形。要不要把这个字分开编码?同样的道理,如果分开编码,在香港生成的有

字的文件,到了大陆可能在文件中就找不到“骨”字了。为了信息的交流,我们希望这个字是抽象的、概念上的字。在还没有计算机的时代,手写的骨字,或者今天写的骨和昨天写的骨,从字形上都会有区别,更不要说老师写的骨和学生写的骨都是不一样的,但是我们可以没有任何障碍地认识这个字并知道它表达的意思。可见我们看到的字的样子,从认知层面已经转换成了抽象的骨字,而不是一个具体的字形。再比如这个月字的撇,我可以写的比较长,或者歪歪扭扭,没有人会觉得它们有什么不同。把不同的具体字形转换成抽象的字就是我们所说的在认知层次的认同。
再举一个“鹅”字的例子,大家平常用的鹅字有四个不同的写法。虽然部件相同但相对位置不同,在ISO 10646中都分开编码。如果你平常没注意,有一个人把这个“鵝”写成“鵞”,你大概还是会说它是鹅字。因为我们对汉字的认知是表意的,可能你看到“䳘”这个字的时候,会愣一下,但是细想觉得除了表示鹅这一动物也没有什么别的意思,也可能会想它是不是某种品种、类型的鹅,而实际上它们都是异体字,有相同的部件,只是这些部件的相对位置不同。从这个意义上说,中文字本身就是抽象的。汉字书写有二维性,它不像英文是一维的序列,汉字则是部件的二维组合加一维序列。大家看到我把简体字的鹅字也列了出来,但是这几个繁体的鹅字所对应的简体字,我们并不希望被编码,因为它们在历史上不存在,否则的话类推的字都编码会使用太多资源,也不利信息交流。另外还有一种异体字,它的部件不同,但表达的意思相同。比如说“雞”和“鷄”这两个繁体字,一般人都知道其表达的字义相同,因为两个部首都表示鸟类,而奚是声旁,所以大家都能够认出来。我们做编码的时候,就要考虑这些字需不需要认同。这四个表示鹅的繁体字,当时都没有被认同,原因就是大家觉得从结构上看,它们的相对位置都有一些很明显的改变,如果把它认同了,以后这些字的不同异体在电脑上就没法表达,这对做古籍研究的人来说,意味着有一些信息没法支持。所以当年在大字符集的编码时有一个认同规则,即结构不同的异体字分开编码。而骨字作为一个基本的概念,没有一个地方会用两个不同的写法,所以就把它都认同了。
我们在界定认同规则时,在字符集的大小上选择上是有矛盾的。在最早做标准的时候,希望字符集小一点,这样字容易找一些。换句话说,作为一个通用的字符集,字太多了查找时会对用户造成困扰。比如字符集有40,000个字,那么很多字可能都会相似,这样用户输入时的选项会太多,系统上的输入法也可能因为要支持太多字而变慢,最终降低输入的效率。所以在字符集制定时,要考虑它是通用还是特用。如果是通用,少一点类似的字,方便大家的基本交流,比如鹅这样的字,最早的GB 2312只收一个简体字,更方便交流和沟通。而特用可能有不同的要求,跟通用是不太一样的。比如说做古籍的出版,字没有编码就无法方便地呈现各种不同的异体字。通用与特用之间的矛盾与应用有关,无对错之分。
另外,汉字字形有一个和时代相关的特殊性,由于书写工具的改变,汉字字体产生了变化。汉字笔画因为不同工具和不同审美使字形出现了很多差异。从制定标准的角度,这就提出了需要选择所谓正字的问题。换言之,同一汉字有不同写法,要选择一个大家都比较接受和最常使用的字形,这是为了方便沟通。这个“正”不是对错,也没有动词调整的意思。
所以汉字在编码的过程中一定要有认同。完全没有认同,看见一个样子就去编码是不可能的,因为这样就变成了字形编码,而不是字符编码。符号是为了交流的,所以做编码的过程中要注重它是一个字符,而不是一个字形。字形是靠什么固定的?字形字体通过字库来支持。有了认同规则,有助汉字的索引,在查找时会方便很多,这也说明对三个骨字的字形编码和对一个骨字编码的区别。
在早期编码时,我们还要认可已成为既成事实的编码字。比如户字有两种写法:户和戶,该字的异写性质跟骨字一样,也应该只给一个编码。但是在ISO10646标准中却被分开编码了,这是因为中国台湾在最早制作汉字标准时,把它们分开编码了。计算机里用这个编码体系所生成的文件把这两个异写字形当作了两个字,在制定ISO 10646时,只能把它们作为既成事实接受了,这是为了保证用台湾的源代码所制作的文件能够在ISO 10646平台上使用和复原。所以在认同规则里有一个称之为源代码分离的规则。这些字形如果不是因为源代码的分离已成事实,原本都应该被认同的。
认同原则不仅通过规范的原则提高了用户的使用效率,也减轻了对系统资源的影响。但是认同作为标准化审议的必经过程,编码本身的过程也会增加很多的工作量。比如方正集团作为造字商在计算造字的工作量时表示,如果以两百万字作为基本工作量单位,那么制造两万字的工作量则要远超10倍。因为除了单字的制作成本,还要检查字与字之间制作的一致性。
(二)现有编码方法的局限
汉字编码有什么局限性?原则上汉字编码要遵从唯一性原则,比如说户字,就应该只有一个码。但是,唯一性有时还是要让步,因为作为新的国际标准,也要尊重既成的事实。编码技术也不是一蹴而就的,编码技术也是在标准的开发过程中通过因应不同需求和解决不同问题而逐渐进化和成熟的。早期的汉字编码面对继续推出的压力,要在很短的时间内编码。后来才发现有些东西如果当时有时间稍微再考虑一下,可能会更好。但是要有超前的思维很难,虽然技术发展很快,但要求的改变更快。汉字编码技术最大的局限是从一开始就确定了一字一个内码。而汉字的内码跟其属性之间的关系非常弱。虽然内码的编排是遵循了汉字的部首和笔画排序,但因为字符的添加是批量进行的,所以新一批的内码编排和前面已收的字在排序中完全断了,换言之,几乎不能根据一个给定的内码,来推断它的部首和笔画信息。
对于汉字的发音是其另一个属性,但是标准里的汉字是一个中日韩汉字的集合,有些是中日韩越的通用汉字,也有韩文、日文甚至是越南的独有汉字,因此即使是同一个字也会有不同的发音,而这些信息在内码的编码层次上是没有办法表达的。
另外,字和字之间,特别是异体字之间也没有办法直接关联。内码本身一个码带不了这么多的信息,所以这些信息通常要通过一个附加的数据库来提供关联信息。因为异体字有关联了以后对查找会有很大帮助,特别是在古典文字学习和研究的过程中。比如,看见一个鸡字,能不能知道汉字里有几个鸡字的写法。但是异体字的问题在不同地方关联的关系又不尽相同,这也增加了提供这种信息的难度。
总体来说,现有编码方法的局限主要包括:(1)唯一性的争议;(2)相关信息的缺乏;(3)错字的问题(有一些既成的错误已经存在于计算机编码里);(4)编码的效率问题。ISO 10646的汉字编码字符集目前已经面对严重的效率问题,因为它已经有70,000多字,且互相之间没有关联信息,所以查找起来效率较低。另外还要考虑通用性和特用性的平衡。从某种意义上来说,认同提高了效率和交流,但在另一方面也限制了应用。在古籍数字化的工作中,如果为了传播、交流、学习和普及,希望不要用那么多异体字,而是用规范汉字。但是如果是做文字研究,比如说写一篇文章想讨论中国大陆、中国香港和中国台湾的汉字差异,那么如何将已经认同的字的差异印出来,就要寻找一些特定的解决方案。原则上,系统要安装三个字型(font),大陆、香港和台湾用的字型都要在工作电脑上。
(三)更适用于异体汉字编码的关联编码技术
今天还要介绍一个汉字关联的编码技术,在ISO 10646标准中称之为Ideographic Variation Sequence(简称IVS),即异体字序列表示法,使用这个序列表示法进行异体字的编码,要理解其中几个概念。一是如何关联。既然是异体字,那么它们通常相互异体,并非说哪个字更重要,但一般比较常用的那个字已经编码了。通常我们称那个已经编码的字为基本字,不过也有可能几个异体字都已经编码了,所以选哪个做这个基本字要根据一些原则。通常是选最常用的,或者用户最容易联想到的那个字作为基本字。
第二个概念是Variation Selector(异选符)。ISO 10646在U+E0100到U+E1EF里定义了240个异选符。一个基本字的后面加一个异选符成为一个编码的组合序列,可以用来指认(定义)这个基本字的一个特定异体字。该异体字的组合序列需要注册以及标准组织的确认。原则上一个汉字可以通过这种方式定义最多240个异体字,远超实际需要。
需要指出的是,一个相同基本字所拥有的两个不同的异选符也不能表达它们所代表的异体字之间的区别,因为这种信息不是编码层面能提供的,具体的差异和审批需要经过专家的审议和批准。用异体字组合序列来定义汉字同样要遵循编码唯一性的原理,因此一个异体字不能有两个不同的异选符的组合序列。每一个异体字对应的组合序列是唯一的,是一种组合式编码,而且现在在系统上已经可以支持。它能够提供的是对基本字的关联性。现在主要的电脑系统在其最新的操作系统上都已经开始支持汉字的异选组合序列这种技术。
在技术上实现异选序列还有另外一个好处。在电脑上为了能使一个汉字用于交流,我们首先必须通过标准化的工作给该字编码,然后字库厂商要把它加入现有字库,最后用户才能在应用时使用该字。但是字库的开发一定会慢一步,因此如果有一些系统上的字库只支持基本字,而当你的文件中使用了异选组合序列,系统上肯定找不到它的font。然而,因为序列里有基本字的编码,系统上可以显示基本字,这样的话不会因为找不到一个序列的字形就把该字变成空框,也就是说基本字在显示时充当了临时替代的作用,但是内码还是一个序列。当字库更新了,这个字就可以正确显示而无需对原文件做任何修改。这是组合序列的一个好处。也就是说这种组合编码方法使该异体字和基本字有了关联信息,或者可以称之为次关联,所以替代后就可以自动实现。
虽然异选组合序列对汉字编码而言是一个新的技术,但组合序列的表示方法在计算机使用的初期就一直在运用,最早的计算机系统里只有很有限的128个码位来定义字符,而当时的128个符号使用的是ASCII字符集,包括了英文大小写字母和一些基本的标点符号、数字等。从那时起系统就已经使用组合方法表示这128个字符之外的符号。比如想要显示“小笑脸”,所输入的是一个特定符号序列冒号和一个右括号,系统见到这个序列就会显示小笑脸。即使到今天,打这个序列,系统还是会显示小笑脸。所以两个码的序列可以定义一个特定的符号并不是新技术。
另外,这种组合方法只表示有相关性,并不要求异体字与基本字的字形一定要有相同的结构,也就是说对是否使用认同规则没有要求,提交者可以根据应用自己进行定义。比如,作为汉字研究的小学,我们可以专门定义一个集,在小学的研究上可以更灵活的定义和处理异体字。在做通用的应用中,也可能使用其他的定义,也就是说允许不同层级的定义,从而增加灵活性。
实际上汉字的IVS技术现在已经在电脑上实现和应用了,Adobe在日本的字库就使用了IVS技术。比如日文的“辻”字还有一个异体的写法。原本根据认同规则,第二种不常用的字形无法编码,也无法使用。使用了IVS技术将其用异选序列表示,这个异写的字形可以得到支持(图2)。

IVS的应用范围以及关联信息相对来说比较明确,与基本字是唯一对应的关系,且该关联信息可以在系统底层给予支持。只要系统支持,对使用者来说就会方便很多。也可以作为一个特用的字符集,为文字研究工作者的使用提供方便,因为关联信息对于文字研究的人来说比较容易理解,也有使用需求。对普通的用户来说,则可以减低噪音和提高效率,因为输入时可以减少异体字的选项。用IVS技术的另外一个好处是,编码的周期也相对较短。
在技术上说,一个字对应两个码似乎是一种非定常的表示,但是对于用户来说,如果在系统层面上有支持,那其实对一般使用没有任何影响。由于是新的技术,IVS技术只在最新的系统上有支持,如果系统版本较旧的话,是不能支持IVS技术的。因此要使用这一技术,系统的更新换代是不可避免的。
在古籍文献数字化中,汉字编码主要是帮助特定领域的研究和应用,而不是为了通用。在异体字整理的过程中,使用者对基本字的认可一般没有异议。也就是说,在整理的过程中,我们常常会很自然的说一个字应该是某个字的异体字。一般而言,基本字是相对稳定的。当然,标准制定中仍有一个选字的过程,而使用IVS的好处是,选字的过程其实与古籍文字的整理工作具有很高的一致性,因此编码速度会相对较快,需要注意的反而是已用IVS技术定义的异体字不能重复。基础字的关联在编码层次上实现之后,对于系统和后续的应用开发有很大的帮助。换言之,编码之后,无需在每一个应用上再做一个异体字的信息库,从而在应用上减少信息重复,也提高开发效率。
使用IVS技术之后,同一个基本字的异体字就可以自动排在一起。这样不仅方便排序,也利于查找。当然有可能会把一些异构和笔画不同的字排在一起,有些用户可能不习惯,但是对于文字工作者来说,只要你理解了这个概念,就会觉得其实还是挺方便,因为找同义字会更方便。
可以预见到的一个问题是,如果一个字跟不同的字有关联,那我们应该选哪个字做基本字。有一种提法是,如果字之间的关联较弱,或者每一个关联都不太强,可以不用IVS技术编码;如果一个字有两个或以上的意思跟两个不同的字有部分异体关系,这种情况可以选其中一个较常用或关系较稳定而且大家都接受的基本字,当然也可以选比较常用的那个字。当然,字与字之间关系在不太确定的时候,可以推迟它的编码。我在这里举一个例子,正好前两天我遇到关于“瓷”“珁”“瓨”三个字之间关系的讨论。“瓷”是我们平常用的,但“珁”和“瓷”实际上是同义词。虽然“瓨”跟“珁”的字形更像,但在意思上是有区别的。所以对于这几个字的关联,或者能否关联有一些不确定性。
今天所介绍的IVS技术对古籍的整理、研究和数字化很有帮助。也就是说,古汉字的编码还有另外一种编码方式可以选择,而且在使用上会更便捷。
方正电子在超大字库方面的探索和实践
张建国(北京北大方正电子有限公司)
方正电子起源于王选教授发明的汉字激光照排系统,在成立至今的30多年里一直服务于新闻出版印刷行业,是国内最大的中文字库厂商,曾被国家版权局授予“全国版权示范单位”称号,也是科学技术部、中央宣传部、中央网信办、文化和旅游部、广电总局联合打造的国家文化和科技融合示范基地,并与教育部和北京大学共建了中国文字字体设计与研究中心。
到目前为止,方正电子有中文简、繁体字库2,000多款,GBK字库(21,003个汉字)116款,GB 18030-2000字库(27,533个汉字)78款,超大字库(80,000多汉字)6款。
方正电子最初开发超大字库是为了满足辞书出版的需要,《汉语大字典》(第一版)的汉字数量在56,000多字,方正的超大字库产品包含了宋一、楷体、中等线、新书宋、新楷体、兰亭黑等字体的汉字80,000多个,解决了辞书出版的难题。后来,国家要求更换二代居民身份证。一代居民身份证的姓名、住址等信息都是手写或打印,卡片中不带芯片,但是二代身份证的卡片内部含芯片,内容以编码形式存在于芯片中。当时方正电子受公安部的委托开发了人口信息字库,目前该字库还适用于护照、银行卡、社保卡等许多与人名地名相关的应用场景。
方正电子还一直在参与中文编码相关的国家标准和国际标准的制定工作,并且依据相关标准不断扩充汉字编码字符集,收录的汉字量已经从最初的6,763个跃升到93,888个。
方正超大字库产品已有20多年的发展历程:1997年,方正电子为《文渊阁四库全书》电子版提供了楷体字库;1998年,开发了宋一体大字库,包含《汉语大字典》56,000字;2001年,“中国基本古籍库光盘工程”采用方正楷体字库;2001年,微软新产品Office XP选用方正超大字库(宋体—超大字符集);2001年,方正宋一超大字库(70,000多字)通过国家新闻出版署鉴定;2004年,受公安部委托,开发第二代居民身份证使用的人口信息字库;2016年,推出《兰亭字海》3.0版本,支持80,679个汉字,包括康熙部首、CJK部首、扩展A、扩展B、扩展C、扩展D、扩展E;2021年,扩充为方正超大字库,支持90,000多个汉字,包括康熙部首、CJK部首、扩展A、扩展B、扩展C、扩展D、扩展E、扩展F、扩展G。
以公安人口信息字库为例,2004年收录了汉字32,220个,2010年增加CJK统一汉字扩展B,2014年增加支持通用规范汉字,2018年增加港澳台居住证用字,2021年收录汉字达75,597个,全面解决了二代身份证人口信息涉及的人名、地名生僻字问题。
目前,方正电子正在参与国家“中华字库”工程建设,承担的新书宋、新楷体开发任务已至最终阶段,收录超过300,000汉字,在此过程中,中间字库收录近800,000汉字。因为收字的规则存在差异,后续可能还需要依据相关的国际标准和国家标准完成进一步的整理和认同工作。
方正超大字库在生僻字方面的实际应用包含古籍、辞书出版、人名地名等领域,但也存在以下五个方面的问题:显示问题、输入问题、存储问题、(不同系统之间)交换问题、多环境多设备问题。解决方案也分为几个板块,扩充方正超大字库解决显示、打印、输出问题,设计方正超大字库输入法解决输入问题,开发方正书版、方正飞翔软件与古籍整理平台应用于书籍的出版。
在显示问题上,方正的解决方案是扩充方正超大字库,收集各种字并将其转换为编码字形。目前的字库全面支持国际标准ISO/IEC 10646:2020(Unicode13.0),其中包括基本集、扩A、扩B、扩C、扩D、扩E、扩F、扩G,支持通用规范汉字,汉字总数达93,000多个。
在技术上,方正电子的TTF/OTF字库可适配Windows、Linux、Android、ios等操作系统,适用场景包括C/S应用程序、数据库服务器、手机App(移动端原生App)。另外,云字库可用于服务器端部署,本地不需求配置字库,无需安装,能够实现动态拆分、即时下载显示,适用场景包括Web系统、小程序,手机App(内嵌H5App)等。
在输入方案上,方正专门开发了方正典码输入法,主要解决生僻字输入问题,作为常用输入法的补充。所谓“典码”,类似于查字典,通过输入部首、笔画、笔顺等特征快速定位,直观地录入汉字,操作简便,易于掌握。适配系统包括Windows、Linux、iOS和Android。
针对用户在Web应用和移动App上的使用需求,方正也提供了相应的服务,用户可以在服务器端接入封装的SDK,实现生僻字的输入和展示。该功能基于Web Font技术,即时启用,即时输入,整个过程中用户无需安装字库和输入法程序。其应用场景有Web应用系统、微信小程序、内嵌H5页面的App等。
在网上(Web/H5)应用系统中,只要满足应用系统升级支持Unicode,数据库迁移升级支持Unicode的运行条件,Web/H5网站都可以正常接入,接入方式为引用原生JSSDK插件。在手机App应用中,应用系统升级支持Unicode,数据库迁移升级支持Unicode,安卓系统4.0及以上或iOS系统9.0及以上,都能接入,接入方式为原生SDK和React Native SDK。
另外,方正电子还推出PC端、Web端、移动端、小程序等多种适配服务,以满足用户多环境、多场景、多种设备的生僻字使用要求。Windows XP及上版本、Windows server 2008及以上版本、iOS、Android、统信UOS、中标麒麟等操作系统均适配。目前,大多数应用系统仅支持GBK编码,数据库字符集仅支持GBK,导致超出GBK范围的汉字无法正确显示、存储和交换,这对于古籍整理、人名地名信息录入等工作而言是远远不够的,因此需要使应用系统升级支持ISO 10646(Unicode),使数据库迁移升级支持ISO 10646(Unicode)。
在出版方案上,方正电子开发了“方正书版”和“方正飞翔”软件。方正书版是专业书籍排版软件,采用批处理的排版方式,排版速度快,具有强大的文字处理功能,版式多样,适用于期刊、辞书、典籍、科技类和文艺类等书刊的编辑和排版。方正书版具有适合古籍出版的多种特色功能:支持超大字库、支持长文档、快速抽取词条、快速制作正文中注释效果、灵活多样的标点处理方式、古籍书中的着重效果等。
方正飞翔是一款交互性更强的专业桌面排版软件,能够针对图书、期刊等纸质出版物的排版以及epub电子书的制作与输出,提供专业的版面编排设计功能。它采用简明的组件化布局、时尚的扁平化图标,排版效果所见即所得、用户体验友好,提供文字处理、图形图像设计、公式排版、表格制作等多种功能。方正飞翔也具备适合古籍出版的多项特色功能:支持超大字库;纸电同步出版,可输出PDF用于印刷,同时输出epub、HTML5等用于数字出版;支持目录、索引、脚注、文本变量、书签、专用词等长文档与书刊排版专用功能;支持自动化表格灌文、表格框架、样式应用、查找替换等便捷操作。对长文档的高效处理能够大大提升书刊排版效率。
方正还开发了以XML数据为基础、全流程、数字化的古籍整理平台,整套系统包括底层的技术架构支撑平台、古籍采集加工管理平台、古籍运营发布平台、古籍数据库应用平台。其中,古籍采集加工管理平台支持古籍采集加工、古籍内容管理、知识图谱管理和辅助语料管理,古籍运营发布平台包含用户中心、电子商务、数据库产品制作、运营工具、运营分析等板块,古籍数据库应用平台有在线数据库、移动数据库、微信公众号、镜像数据库、开放接口平台等呈现形式。
最后介绍一下“中华精品字库工程”,该工程于2017年启动,是中华优秀传统文化传承发展工程支持项目,由中国文联、国家语委共同指导,将精选100位中国历代书法名家的代表作品,开发成电脑字库。中国书协负责字体的遴选和质量审核,方正电子负责字库开发。截至目前,已经累计推出35款精品书法字库,如颜真卿楷书、柳公权楷书、黄庭坚行书、赵佶瘦金书、苏轼行书、鲁迅行书等。
近期,“中华精品字库工程”发行了《方正甲骨文·十二生肖》的NFT数字艺术品,总共发行6万份,首发秒空,所有收入全部捐赠中国光华科技基金会,我们也希望能够通过数字的手段进一步弘扬甲骨文,弘扬中华传统文化。
基于古籍出版及数字化的字符整理实践
朱翠萍(古联数字传媒科技有限公司)
古籍出版常常面临着多种字符集问题。
(一)字符集类型多样
因为古籍出版涉及的时间跨越千年,我们所面对的字符不仅“有古有今”,从甲骨文、金文、小篆到楷书(异体字)都有可能遇到,而且“有中有外”,包括汉字、梵文、巴利文等语言,并且“有字有符”,比如一些琴谱、符箓。
(二)异体字的字际关系复杂
在处理一个字的时候,我们需要考虑它的定位,根据它的使用场景选择性地使用相应的字形。
若从造字的角度来看,首先要分析它是异体字还是同形字,如果是异体字,则根据相似度进一步分为全同异体或部分异体,或者根据差异程度分为异写或异构字;如果是同形字,又分为造字偶然同形或变异同形。一般来说,如果一个字是异构字,便不会采取认同的方式;如果是笔画层面的异写,多数情况下会进行认同,但如果要对字形本身进行解读,那就必须尽可能去呈现它本来的面目。
若从用字的角度来看,我们可能面临假借字和分化字两种类型,假借字要考证它是无本字的假借还是有本字的假借,分化字也要对其分化过程进行考证,分析它是借用同音字分化本义或引申义,还是利用异体字分化,或者是用新造字分化本义或引申义。除此之外我们还要考虑字的历时演变与政策规范,比如繁简字形、新旧字形、印刷通用规范字形等。
我曾经在李国英教授的带领下,与同学一起做过《汉语大字典》的字际关系整理工作,对《汉语大字典》中的字头逐个考证,并把台湾“异体字字典”数据平台的考证结果也吸收进来,希望能够对古代的所有字形进行字际关系上的关联,形成一个比较完整、全面的异体关系整理平台。王立军教授团队也开发出“汉字全息资源应用系统”,在该平台上对字的形、音、义、码都进行了界定,部分文字还做了系联,形成了可视化的知识图谱。
(三)终端需求不同
手机、电脑及各类社会应用系统,都属于不同的数字终端。不同终端对字符集要求是不同的。例如出版领域的排版软件,中华书局首选的是方正书版,排版效率非常高。但面对特殊稿件也存在一定困难,例如对《大藏经》进行排版时,书中有大量的悉昙体梵文,但在方正书版中没有梵文字体,如果让排版人员去造字,效率就会变得很低,而且由于梵文作为表音文字,字形之间有时差异很小,又因为梵文是一种陌生的文字,让排版人员造字很容易出错。所以,我们会专门去制作字库和输入法,让专业的人员将正确字形输入出来,将正确的文字稿件连同字库、输入法一并交给排版人员,以避免因为文字陌生而导致不可控的错误发生。另外,我们在选择排版软件的时候,会在字符集大小与排版样式之间进行平衡,如果选择了一个大的字符集,那么它的版面样式可能相应地减少了,如果需要大量造字的话,那就只能选择一个字库最大的样式,来进行呈现。
终端领域的第二个问题是数据库的显示、检索问题。如果只有大量的字图而没有超大字符集支撑,就无法体现数据库的优势,数据库主要服务于检索和统计,甚至进一步实现可视化和结构化呈现。但如果是以字图的方式存在(包括一些结构表达式、部件组合),或多或少会对显示和检索的效果造成不利影响。所以,在古联的数字化产品中,一般不会保留字的部件描述,要么进行认同,要么去造字,只有在极其特殊的情况下才使用字图。
第三,在校对软件终端对书稿进行校对时,软件的主要功能是针对错字、繁简字进行排查,新旧字形需要统替,而这些都提前进行了字表内置,但是《古籍印刷通用规范字表》施行后,编校软件中的新旧字形表也必须进行调整,使之在符合规范的情况下开展编校错误的核查。
终端领域的第四个问题是在智能工具训练方面。有些智能训练工具与字符集也是息息相关的,比如OCR,如果字符集太小,那么很多字是无法识别的,如果字符集过大,很多的字相似性也很大,区分度不高,所以在OCR的训练过程中也需要寻找一个平衡,目前研发者大多选择两万至三万的字符集规模。
繁简转换工具主要用于字形的转换,它在研发过程中最关键的环节不在于转换本身,而是字形整理。繁简字现象是人为改革的结果,是汉字政策的结果,而非汉字自然演化的结果,为了方便使用,它通过类推简化、同音异音代替、草书楷化、换用简单符号、保留特征或轮廓、构成新的形声字或会意字等方式,将一些笔画多的繁体字用笔画少的简体字来进行书写。我们在做书稿的繁简转换过程中就会遇到这样一类问题,以“龜”字为例,众所周知,它可以被转换为简体“龟”字,但是该字有大量异体写法,我们首先必须建立这些异体字与它的关联,当它被转换的时候,与之关联的字也会随之而转换,而不会遗漏。此外,还存在一个同字异码的问题,如果一个字有多个编码,将这个字形进行繁简转换,前期不在编码层面做好统一工作的话,本来应该是两个字之间一一对应的转换,可能会出现多种不同的结果。另外还有这样一种情况,我们在使用系统批量筛查繁体字错误时,将结果导出,却发现导出文件中无法显示错误字形,无法确定错误的字是什么。于是推断这个字可能不是常用字库中的字形,但还是要结合上下文进行考察,一些常见字形如果使用了私用区提交的编码,也可能无法显示。这也说明在做繁简转换时,编码问题是不可逾越的一关。
王晓明老师曾经做过一个逻辑非常严密的“繁简转换字形关系示意图”,作为繁简字表整理的体系规范。首先进行编码层面的认同,然后将无原则类推简化字还原回去,再请专家做异体字的考证和认同,以及字形的关联,最后再进行繁简转换工作,这时候需要考虑是一对一的转换或一对多的转换,还是不转标记简形或不转标记繁形等情况。我们开发的一些自动处理工具都是与字符编码息息相关的,都逃不开这一环。在籍合网上,繁简转换(http://transform.ancientbooks.cn)看起来是一个简单的输入文本、得到转换结果的过程,但是后台是有一套严密的系统或者说字表体系在支撑。
(四)文字规范多维
出版面对的文字规范有多种,有新旧字形、简化字、通用规范字和古籍印刷用字,简化字的相关问题前面已经说过,通用规范字更多适用于现代社会大众生活,我主要谈谈新旧字形和古籍印刷用字。1965年发布的《印刷通用汉字字形表》规定了通用字的形体标准,消除了印刷体与手写体之间的笔画、笔形歧异,使印刷体接近手写楷体。《新旧字形对照表》就是根据这个表制定的,其中的“新字形”就是规范形体。在我们以往的古籍整理工作中,一定要用新字形统替旧字形。但是从《古籍印刷通用字规范字形表》发布并实施以后,由于我们要处理的对象是古籍,就不仅仅要考虑字形的新旧问题,还要考虑在某部古籍中哪一个字形正确或者更合适。所以,在这种情况下,以前梳理出来《新旧字形对照表》内置到后台即可,现在可能在“选择字理明晰或变异度较小的古籍常用字形,以承袭传统,便于学习”的情况下,就会保留旧字形,不再统替为新字形。
(五)中华书局及古联公司的字符整理实践
中华书局很早就开始进行字符整理工作。2003年中华书局、商务印书馆承担新闻出版总署的“新闻出版用汉字大字符集”项目,全面调查统计出版界的汉字使用情况,充分利用现代信息处理的手段,整理与标注汉字的各项属性与参数,建立相应的数据库。2006年,中华书局、商务印书馆承担信息产业部电子工业化研究所“信息技术中文编码字符集汉字排序(笔画序和笔顺序)”项目,项目规范是GB 18030-2005/GB 13000统一汉字字形排序标准内容之一,其数据内容包括:汉字字形,笔画数,笔顺,汉字的GB 18030、GB 13000代码,汉字来源(CJK)等。2008年,中华书局组织建设了“图书馆汉字规范处理”项目的汉字属性字典规范,以及古籍用字(包括生僻字、避讳字)规范(计算机用字标准),提供了全部国际标准71,306个汉字的属性数据和81,958个古籍用字的属性数据(包括汉字的古今读音、部首、笔画、编码、异体字、避讳字等相关属性),以及构词和使用频度等相关信息。中华书局还为ISO 10646信息交换用超大字符集扩展C、扩展E集提供了2,000多个历史考古文献、方言用字等现代出版物用字。这是在古联公司成立之前中华书局主要在做的工作。
中华书局数字资源部到古联公司成立的过渡时期,一直在参与的项目还有“中华字库”工程的子课题12包和16包。12包是与清华大学联合进行的“宋元印本文献用字的搜集与整理”工作,16包是“现代的汉语出版物用字及专门用字、非字符号的搜集与整理”,此外我个人还参与的“11包”是版刻楷体字书文字整理。这“三包”共同使用的一个规则是“楷书字形选取规则”,大方向上是从结构、部件、笔画这几个方面来进行考量、认同,其中笔画层面分歧最小,多数趋于认同。结构和部件两方面更为宏观,更倾向于别异。
同时,我们也面临一些非字符号的难题。在我们所面对的非字符号中数量最大的是古琴减字谱,梳理出来大约有五六万。对于这种特殊符号,也有专门的处理规范,首先要从文献中将它们采集出来,进行指法上的注释,然后赋予它们编码并开发专门的输入法,从而实现非字符号的顺畅输出。
在参与前面这些国家项目的基础上,中华书局和古联公司在古籍数字化工作中形成了较好的字库建设经验。目前籍合网上公布了三种字体,中华书局宋体字库、中华梵文悉昙体、古联甲骨文摹写字库。宋体字库中也包含一些小篆、金文及其隶定字。后来随着外文符号或古文符号的体系化,并且这些符号数量也较大,为了做好这个独立的产品,我们专门给它做了配套的字库字体,截止到目前字库中约有150,000字,当然其中有一大半基础字形是方正字体。
之所以研发独立的中华梵文悉昙体,是因为大量的悉昙体梵文占用了跟汉字相同的编码,容易造成显示上的混乱,为了避免这种混乱,我们请通晓密教文献、悉昙体梵文并擅长书法的专家崔文治先生写了一套梵文字体,又找了四位懂梵文的专家对其进行拉丁文转写、辨识,确保能认、能读,最后再配套梵文输入法,这样就能够把一套书中的梵文都准确无误地显示出来。
另外,我们做甲骨文相关数据库时也开发了配套的甲骨文字体,用于支撑产品的阅读和检索。这样就形成了中华书局超大字库的整体面貌,其中有宋体,有甲骨文,有小篆,有梵文,还有其他的一些非字符号,等等。
在字形的处理和选用过程中,还需要考虑与数字化产品适配的问题,也就是说,面对数十万字的字库,到底选用哪种字形、怎么处理才是最合适的?对于一般文献,我们尽量采取认同的处理方式;对于小学文献,则尽量保真;对于敦煌文献,如果写经卷子里存在大量的俗字,也会对其进行保留;对于出土文献,则要根据工作优先度区分对待,有的需要造字,例如甲骨文,有的使用隶定字,有的与楷体字形认同,有的字如果出现频次不多的话就以字图方式保存。
中华书局和古联公司在字库工作经验积累的基础上,建设了一系列的文字类资源库及平台,如文字属性整理平台、殷墟甲骨文数据库、金文词典编纂平台、小学文献数据库。
以往处理不同批次的文献以及不同人同时处理的字符,基本在word文档中进行,采取宏命令的方式进行标记,但难以避免不同人处理相同字的重复问题,随着外字业务量的扩大,我们搭建了文字属性整理平台,以处理不同批次的文献以及不同人同时处理的字符。该平台可以将文字提取出来并进行基本考证和属性描述(包含形、音、义、码位、出处、处理方式、关联字形等信息),然后提交,进行排重,最后再回填成为处理后的数字化Truetype字体。在配套的字符查询工具中,也提供了新造字的字符查询方式。字符查询工具主要服务于疑难字的查找,通过查找部件的方式检索到某字。因为很多字是音未详,或义未详,或音义皆不详的,几乎不可能通过读音或部首查找到它,所以在处理古籍的过程中,主要使用构形查询的方式来检索疑难字。这些文字整理的相关工作基本上是配合资源库产品开发而开展的。
我们开发了殷墟甲骨文数据库,包含拓片释文、甲骨字典等。另外,为配合《金文大辞典》出版,我们优先介入编纂环节,使金文的切字、词条的整理、文字的考证考释都在金文词典编纂平台上进行;整理任务完成后,审核工作也设置在平台流水线上;全部整理完之后导出的文件就直接输出到图书出版方面。目前正在建设中的还有战国古文字研究平台。此外,已经上线的还有小学文献数据库,其中已经包含小篆字体与所谓的异体字。刚才强调了小学文献一定要保真,因为如果相似的字形没有保真处理的支撑,离开原书只看数据库,可能被说明的对象都不存在了。
总体来说,古联公司所开发的文字类数据库,从甲骨文到金文、战国古文字再到小学文献中的小篆,再到楷书,基本将汉字演变的过程串联起来了。我们希望能够通过这些数据库、字库以及数字资源的研发工作,使汉字从甲骨文到最终形态的演变过程都能在一个平台上找到相应的资源和出处,最后形成集字形、文献、字库、输入法、协同编纂、成果发布为一体的“历代汉字与古文献综合应用与研究平台”。
[1]郑玄注,王锷点校:《礼记注•中庸》,北京:中华书局,2021年,第693页。
[2]许慎撰,陶生魁点校:《说文解字》,北京:中华书局,2020年,第93页。
[3]许慎撰,陶生魁点校:《说文解字》,第494—495页。
[4]班固著,顔师古注,中华书局编辑部点校:《汉书》,北京:中华书局,1962年,第1721页。