毫无疑问,吃货是推动科技进步的一大动力!
让我们从𰻝biáng𰻝biáng面说起?(如果在这里看到的是空白、方块或者问号,代表您的系统无法正确显示该字符)

𰻝𰻝面是流行于中国陕西关中地区的一种知名传统风味面食,属于扯面,通过揉、抻、甩、扯等步骤制作,面宽而厚,犹如“裤腰带”,口感劲道,食用前加入各色臊子或油泼辣子。位居关中十大怪之首,正所谓“扯面像裤带”。
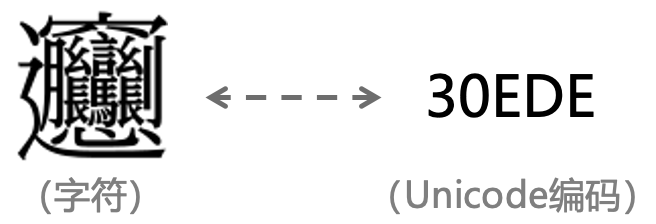
𰻝 这个汉字被收录在2020年3月10日更新的Unicode 13.0版本里,具体收录在中日韩统一表意文字扩展区G区块中。繁体字的编码为U+30EDE 𰻞 ,简化字的编码为U+30EDD 𰻝 。
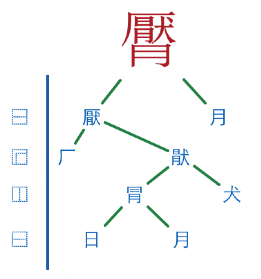
𰻝 还可以表示为(⿺辶⿳穴⿲月⿱⿲幺言幺⿲長馬長戈心),这是一种“动态组字”方法。
动态组字测试:
可选组字描述符 ⿰⿱⿲⿳⿴⿵⿶⿷⿸⿹⿺⿻
什么是字符编码?
自计算机发明伊始,文字处理就成为计算机技术的核心课题之一。世界上主要的文字系统包括拼音文字、楔形文字、象形文字等,如何对其进行编码、显示、识别,一直是非常棘手的问题,解决方案不胜枚举。
在计算机系统中,文本通常以二进制形式存储,不同的字符需要分配唯一的二进制编码,从而使得不同的计算机操作系统和软件能够正确地解释和显示各地的语言和符号。最早的汉字编码方案之一是GB2312,它由中国国家标准化管理委员会发布,用于简体中文字符的编码。后来,随着繁体字、港澳台地区的特殊字符以及其他语言和方言文字的需求,GB18030、BIG5等编码方案相继出现。这些编码方案之间存在着不同的字符映射和编码规则,因此在不同的计算机系统中可能会出现编码转换乱码的问题。
随着互联网的兴起,为了满足不同的计算机系统在信息交互时可以正确地显示和处理各种字符,提出了统一字符编码标准Unicode。目前,Unicode已成为信息技术领域的业界标准,由非营利机构Unicode联盟(Unicode Consortium)负责维护。Unicode的出现减轻了过去在不同编码方案间切换和转换的困扰,使得汉字在全球范围内都能够被一致地处理和交换。
然而,即使在Unicode标准下,汉字的编码仍然具有一定的复杂性。例如,Unicode标准中的汉字编码范围庞大,涵盖了常用汉字、生僻字、历史字等各种字符,并且还包括了不同的汉字变体、繁体字、异体字等。此外,汉字的编码还需要考虑到字形和字义的关系,以及不同字体和排版风格对汉字显示的影响。
- 在阅读下文之前,可以先进行设备文化程度检测;
- 如果下文存在无法显示的字符,可以下载全宋体字库 ,了解生僻字显示的原理。
- 历史上不同时期的常用汉字有多少?字典里收录的有多少?
| 文献名称 | 文献用字量 | 字书 | 字书收字量 |
|---|---|---|---|
| 《十三经》 | 6544字 | 《说文解字》公元100年 | 9353字 |
| 18401首宋诗 | 4520字 | 《玉篇》公元543年 | 22726字 |
| 《史记》 | 6000字 | 《类篇》公元1066年 | 31319字 |
| “748工程“2160语料 | 6335字 | 《康熙字典》1716年 | 47035字 |
| 《毛选》1~4卷 | 2891字 | 《汉语大字典》1990年 | 54678字 |
| 新华社86年4000万新闻稿 | 6001字 | GB18030-2022 | 87887字 |
表中的GB18030-2022是2022年7月19日由国家工业与信息化部发布的国家标准,中文标准名称:信息技术 中文编码字符集;英文标准名称:Information technology—Chinese coded character set。2023年8月1日正式实施。对于公众、政务服务来讲,近88000字中级别3的生僻字服务仍存在不少障碍。目前大多数的手机系统只是能显示级别2的汉字,而输入法在手机、PC上几乎全在实现级别1上停留——即便级别2只是增加了不到200字。
「𬀩𬱖𬎆𮧵」这四个VIP字可以用于测试系统的支持程度。IOS 17.4.1版本亲测可以正确显示,但仍无法输入「𬎆」和「𮧵」(2024年4月)。
Unicode编码概述
Unicode的编码方式是将编码空间分成 17 个平面(Plane),每个平面有65536(216)个码点(code point)。
| 平面 | 范围 | 中文名 | 英文名 |
|---|---|---|---|
| 0号 | 0000至FFFF | 基本多文种平面 | Basic Multilingual Plane,简称BMP |
| 1号 | 10000至1FFFF | 多文种补充平面 | Supplementary Multilingual Plane,简称SMP |
| 2号 | 20000至2FFFF | 表意文字补充平面 | Supplementary Ideographic Plane,简称SIP |
| 3号 | 30000至3FFFF | 表意文字第三平面 | Tertiary Ideographic Plane,简称TIP |
| 4号 至 13号 | 40000至DFFFF | (未启用) | |
| 14号 | E0000至EFFFF | 特别用途补充平面 | Supplementary Special-purpose Plane,简称SSP |
| 15号 | F0000至FFFFF | 保留作为私人使用区(A区) | Private Use Area-A,简称PUA-A |
| 16号 | 100000至10FFFF | 保留作为私人使用区(B区) | Private Use Area-B,简称PUA-B |
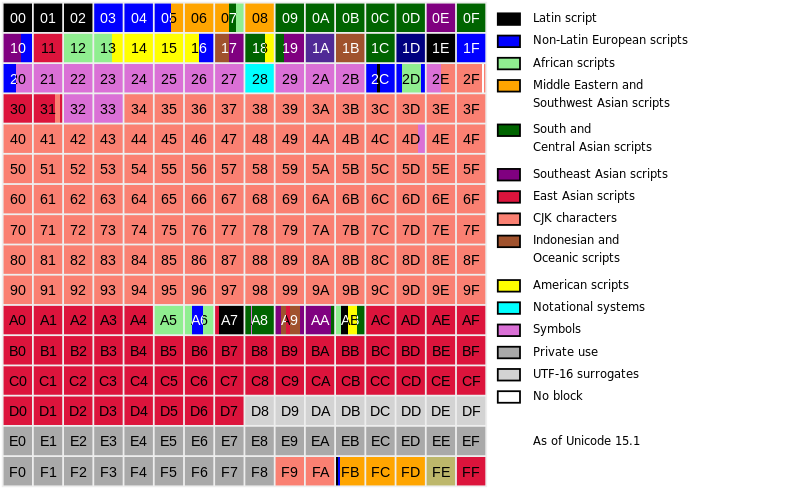
在第 0 平面,即基本多文种平面(Basic Multilingual Plane, BMP),下图中用橙色表示的CJK字符占有了近半数的码点。CJK字符是指基于汉字书写系统的中日韩同源文字。
Unicode的实现方式不同于编码方式,被称为Unicode转换格式(Unicode Transformation Format, UTF)。出于节省空间和提升传输效率的目的,可以选用不同的编码方式。
例如,对于一个仅包含基本7位ASCII字符的Unicode文件,如果每个字符都使用2字节的原Unicode编码传输,其第一字节的8位始终为0。这就会造成比较大的浪费。对于这种情况,可以使用UTF-8编码,这是一种变长编码,它将基本7位ASCII字符仍用7位编码表示,占用一个字节(首位补0)。当遇到与其他第0平面的Unicode字符混合的情况时,可以按一定算法转换,将每个字符使用1~3个字节编码,并利用首位为0或1来标识。类似的,对需要4个字节的辅助平面字符,比如“𰻝biáng(U+30EDE)”位于TIP,即表意文字第三平面,2字节编码的UTF-16也需要通过一定的算法进行转换。
Unicode标准中的汉字字符编码
Unicode编码描述汉字是一个不断发展的过程。Unicode 1.0基本沿用了GBK编码字符集,将GBK编码重新整合为Unicode编码。随着计算机应用范围的不断扩大,原有的GBK字符集已不能满足各类应用场景的需求,因此Unicode描述汉字的范围也随之扩大,大约每隔几年推出一个扩展的汉字字符集,从扩展A、扩展B,一直到GB18030-2022标准的扩展E和F。
每个扩展字符集中的汉字基本是按照214个康熙部首的笔画数来排序的,就是说新增的汉字先归类到各个康熙部首中,然后再去除部首的笔画,按照剩余笔画数来排序,对于简化字的部首,如“言”和“讠”、“金”和“钅”等,在归类时分别作为部首中的两个子类来处理。在完成新增字符的归并和排序后,依次赋予每个字符Unicode标准编码,将新增的编码和字形通过PDF文件的方式公告在官方网站中。

Unicode中跟汉字相关的编码涉及多个平面,统称为UniHan, 目的是为了将基于汉字书写系统的同源文字统一在一起。包含了汉字及其派生出来的意音文字,包括繁体字、简化字、日本汉字(漢字/かんじ)、韩国汉字(漢字/한자)、琉球汉字(漢字/ハンジ)、越南的喃字(𡨸喃/Chữ Nôm)与儒字(𡨸儒/Chữ Nho)、方块壮字(𭨡倱/sawgun)等。官方文档在 http://www.unicode.org/reports/tr38/。
- 如何按不同地区显示这些具有微小字形差异的字符呢?带着这个问题往下看。
在UniHan标准中,除了第0平面的CJK字符以外,还包括第二辅助平面,也称表意文字补充平面(Supplementary Ideographic Plane, SIP),范围在U+20000至U+2FFFF,配置的都是罕用汉字或地区方言用字。还包括第三辅助平面,也称表意文字第三平面(Tertiary Ideographic Plane, TIP),规划用于摆放甲骨文、金文、小篆、战国文字、简帛文、陶文、鸟虫书等古文字,范围在U+30000至U+3FFFF。
在UniHan数据库中不仅定义了每个字的码点和字形,还包含其他信息,如拼音,异体字,笔顺,英文定义,部首,康熙字典部首等。
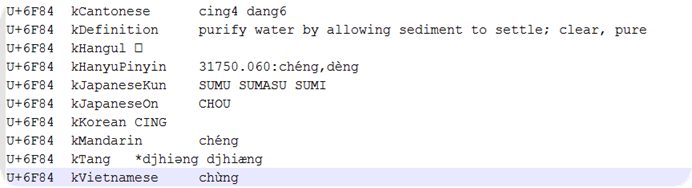
从上图中可以看到:广东话发音kCantonese,英语定义 kDefinition,現代漢語頻率詞典kHanyuPinlu,kHanyuPinyin是<漢語大字典>中对此字的发音定义,kMandarin是这个字在普通话中的常用发音(对多音字有意义), 现代汉语词典kXHC1983,以及其他语种的发音。
字义、字形与字型的编码原则
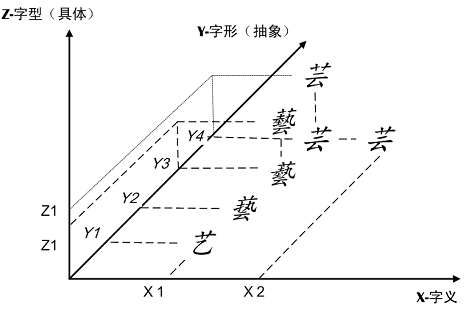
UniHan标准中有X,Y,Z三轴,意思就是所有汉字都可以定位在X,Y,Z三个坐标轴上,这是为了建立各个字形与其含义之间的关系。X轴代表字义,Y轴代表字形(Generic Glyph或Abstract Glyph),而Z轴就是字形的具体造型(Form)。如上图中,中文简体字“艺(U+827A)”与日文简体字(略字)“芸(U+82B8)”,都是“藝(U+85DD)”的简体。与异体字“兿(U+517F)”都具有相同的含义(在X轴的投影为X1),但它们不能认同为一个编码汉字,而是在Y轴上的四个投影(Y1,Y2,Y3 和Y4);同样的,虽然“芸”至少还有一个含义(芸香,芸芸众生,X轴投影为X2),但它不能再有另一个代码。
汉字字形是形式(或“能指”),不是内容(或“所指”);相对于字型它是抽象形态,不是具体的造型。在上图中,“芸(U+82B8)”和“芸(U+82B8-H)”,“藝(U+85DD)”和“藝(U+85DD-H)”,虽然在草字头上有差异、从而在Z轴上有不同的投影(Z1,Z2),但被视为Z轴上的微小差异,不影响其在Y轴的投影,因此代码不变。| Unicode编码 | 中文 | 日本 jp/ja |
韩国 kr/ko |
越南 ni-hani |
||
|---|---|---|---|---|---|---|
| 中国大陆 zh-cn |
香港 zh-hk |
台湾 zh-tw |
||||
| U+85DD | 藝 | 藝 | 藝 | 藝 | 藝 | 藝 |
| U+82B8 | 芸 | 芸 | 芸 | 芸 | 芸 | 芸 |
| U+623F | 房 | 房 | 房 | 房 | 房 | 房 |
| U+76F4 | 直 | 直 | 直 | 直 | 直 | 直 |
上表中不同地区的不同字形是如何显示出来的?
# 第一种方法是利用Html的Language Code来显示
<span lang="zh-hk">藝</span> #香港地区
<span lang="zh-tw">藝</span> #台湾地区
<span lang="ja">藝</span> #日本
#第二种方法是通过css样式中的content属性值,指定要显示字符的Unicode编码;通过font-family属性值,指定对应字库,由字库对应不同地区的字形。
字库可以选用 Noto Sans CJK(含有不同地区的版本的OpenType字库)
# 第三种方法涉及到计算机图形学知识,即字形的绘制,可以单开一篇来讲Font2SVG方法,涉及到如何使用贝塞尔曲线来描述矢量字形。
Z轴字型的这种微小差异,除了上述地区差异以外,还会有异体字和不同书写风格等,可以用Unicode标准中的变体序列(variation sequence)来表示。变体序列由一个基本字符编码后紧跟一个变体选择符(variation selector)组成。
- 变体/异体选择符(Variation Selectors, VS):变体/异体选择符是一种Unicode控制字符,用于指定与前一个字符相关的变体形式。变体选择符紧跟在要指定变体形式的字符之后,以明确表示应该采用哪种变体。变体选择符的使用能够消除歧义,确保在文本中正确地显示所需的字符变体形式。其中,VS15和VS16是专用于表情符号的选择符。
- 表意变异选择符(Ideographic Variation Selectors, IVS):专门用于处理相同字符代码的汉字形状微小差异情况,即“将多个字形放置在同一代码点”。 Unicode 联盟将 IVS 及其相应字形的列表作为表意变体数据库(Ideographic Variation Database, IVD)发布。https://www.unicode.org/ivd/

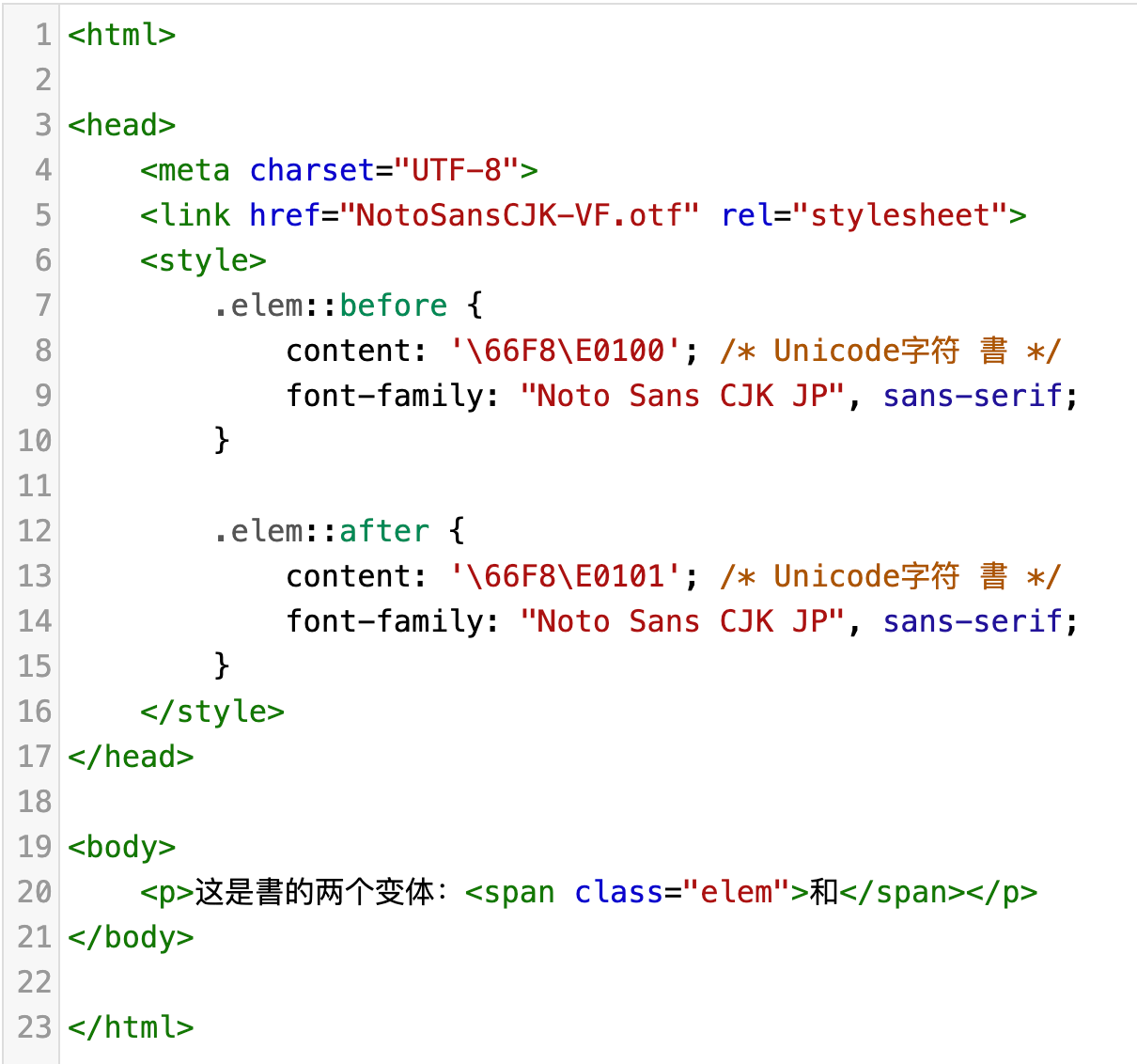
上方两个字形被合并到相同的 Unicode 码位 U+66F8,U+E0100 与 U+E0101是 IVS 选择符。按照上述第二种方法,即通过css样式中的content属性值来指定要显示字符的Unicode编码,该编码后紧跟着 IVS 选择符。注意这里用到的字体库是 Noto Sans CJK JP,因为这个 IVD 是Adobe为日本汉字整理的,相应的会在某些日文字库中得到支持。

如果对照北师大王宁老师在《汉字构形学导论》一书中对“汉字的认同”的定义,她将没有区别意义的字形归纳在一起,叫做汉字的认同。并将共时汉字的认同分为三个层次:字样、字位和字种。上图中的X轴对应不同的字种,Y轴对应不同的字位,Z轴对应不同的字样。
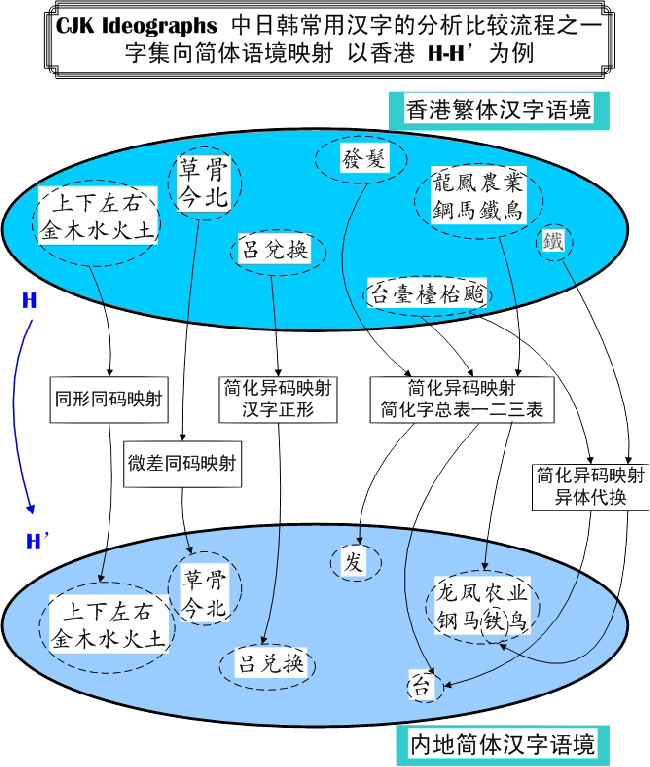
如上图所示,在字位认同(同形同码和微差同码)过程中,存在多种映射规则,往往造成编码分合规则的混淆。接下来分析一些具体案例。
汉字字形编码中存在的问题
1.微小字形差异的处理
各国家/地区间汉字字形的微小差别,有时是很模糊的。即使在同一个字库中,笔画形态都可能有所不同。所以,在微小形差与“同形同码”之间很难准确拿捏,UniHan中存在一些不尽一致的地方。
【了解各个地区的汉字字形差异!-哔哩哔哩】 https://b23.tv/l54OREN
关于「汉字正形 」:1965 年,中华人民共和国文化部和中国文字改革委员会联合发布了《印刷通用汉字字形表》,收6196 字,为统一铅字的字形提供了一个范本。在文字学界和印刷界,常常把这项整理工作称作“汉字正形”。
「汉字正形 」的标准是:同一个宋体字有不同笔画或不同结构的,选择一个便于辨认、便于书写的形体;同一个字宋体和手写楷书笔画结构不同的,宋体尽可能接近手写楷书,不完全根据文字学的传统。按此标准,对有些字形作如下处理,得到新字形。(以下每对字中,左为新字形,右为旧字形)。
- 长方点、斜方点、横点、竖点、撇点改作侧点

- 减少笔数

- 连笔

- 其它

需要补充说明的是:
- 当年的“汉字正形”,基本上是在宋体骨架上进行的,虽然仿宋体和黑体都可参照,但对楷体和其他字体则未作出规定。这样在雨字头、走之的写法上,以及“木”的末笔的笔形(捺或侧点),也就有相当的灵活性。包括马英九先生认为的“英”字的末笔应为点,是因为台湾地区的标准字形中为点,实则是捺或点可以在不同的字体中采用不同的笔形。
- 在上述例子中,凡是有下划线的,新旧字形已经造成了两个或多个Unicode编码汉字并存的事实。
2.收字过少
不同字形之字合并后,若以字形为检索内容,会产生混乱,难以检索。如笔画检字,艸部之“艹头”,中国、日本算作三画,而在繁体中文中为四画,留有“艸”形的古籍中则为六画。UniHan中同一字码的字形不同,即使检出字,笔画与显示出来的字形也不相符。因此,有批评者认为,Unicode合并异体字并不可取。
3.收字过多
UniHan中收录了不少幽灵汉字,其出处难以找到,它们在实际生活也极少机会使用,有些甚至是错讹字,或者仅是某一人的名字用字,那人不见得是名人,甚至可能已去世,却永久成为标准里的字符,占用了一个码位。比如台湾律师吕秋𧽚的“𧽚”字本应作“遠”,可是户政人员误听他外公说的台语,把“辵字边”听成“走马边”,外公又不敢更正。当事人长大后,才确认这是错字,但这个字已永久收进Unicode编码。
对一些异体字进行分别编码,也带来了检索困难。只要写法稍有不同,就无法检出。在用户检索字词时,必须反复检索其不同写法,造成重复劳动,对研究文献反而是一种妨碍。例如UniHan将“兒”和“𠒇”字安放在不同的码位里。在检索文献时,检索“兒”字时就找不到“雷庄𠒇”,检索“𠒇”字时就找不到“雷庄兒”,反而造成困扰。
4.准则矛盾
Unicode编码按各地区原字集分离的原则收字,只看各地区的既有编码,不理会同一部件的文字学问题,产生了不少准则矛盾。在Unicode标准中,早期的异体字时常获分配独立码位;后来常常只有兼容区的暂存编码,使兼容区的字符在输入和显示时经常碰到问题;再后来则不时直接整并,交由变体选择符处理。这样带来了编码矛盾的问题突显。例如:
UniHan对于同一部件有分有合,原则不一,如“眞”和“真”、“塡”和“填”都分离编码,但“縝”和“⿰糸⿱匕具”就整并了;“直”和“⿱十⿺丄目”、“植”和“⿰木⿱匕⿺𠃊目”皆整并作一码,而“値”和“值”又分开,既令人混淆,亦令人无所适从。- 上面三个画虚线的同码字形是如何显示出来的呢?
这里用到的是SVG字形的绘制,可以单开一篇来讲Font2SVG方法,涉及到如何使用贝塞尔曲线来描述矢量字形。
- 还存在许多未被Unicode标准收录的古文字和异体字,又该如何表示呢?
一种方法是利用Unicode中预留的三个私人使用区(Private Use Areas, PUA),PUA 存在的问题是标准不统一、不利于信息交换。接下来介绍另一种方法,动态组字法。
动态组字方法
不同于西方文字系统可以通过字母的线性组合形成单词,再连缀成句。汉字系统是通过构字部件的平面组合形成汉字,再连缀成句的。因为古今汉字数量庞大,包括Unicode在内的字符集都不是完全集。再加上汉字本身具有组合以及开放的特性,汉字使用者很有可能自造新字,因此不可能有一个字符集可以搜集到所有汉字。
这时,可以用表意文字描述字符 (Ideographic Description Characters, IDC) 来描述某“字”如何以较简单的部件进行组合。IDC是Unicode标准中的一种特殊字符,用于描述汉字等表意文字的结构和构造。它们并不代表实际的字符,而是用来帮助理解和编码复杂汉字的组成部分。
表意文字描述序列(Ideographic Description Sequences, IDS)是Unicode标准定义的汉字结构描述语法,描述序列由描述字符IDC与两个以上特定字符组合而成,来描述所定义的汉字内部构字部件的相对位置,从而精确表示生僻字(或尚未被字符集收入的缺字)。
| Unicode编码 | 字符 | 含义 | 例字 | 序列 | 例字 | 序列 |
|---|---|---|---|---|---|---|
| U+2FF0 | ⿰ | 左右结构 | 相 | ⿰木目 | 𠁢 | ⿰丨㇍ |
| U+2FF1 | ⿱ | 上下结构 | 杏 | ⿱木口 | 𠚤 | ⿱𠂊丶 |
| U+2FF2 | ⿲ | 左中右结构 | 衍 | ⿲彳氵亍 | 𠂗 | ⿲丿夕乚 |
| U+2FF3 | ⿳ | 上中下结构 | 京 | ⿳亠口小 | 𠋑 | ⿳亼目口 |
| U+2FF4 | ⿴ | 全包围 | 回 | ⿴囗口 | 𠀬 | ⿴㐁人 |
| U+2FF5 | ⿵ | 上方包围 | 凰 | ⿵几皇 | 𧓉 | ⿵齊虫 |
| U+2FF6 | ⿶ | 下方包围 | 凶 | ⿶凵㐅 | 义 | ⿶乂丶 |
| U+2FF7 | ⿷ | 左侧包围 | 匠 | ⿷匚斤 | 𧆬 | ⿷虎九 |
| U+2FF8 | ⿸ | 左上角包围 | 病 | ⿸疒丙 | 𤆯 | ⿸耂火 |
| U+2FF9 | ⿹ | 右上角包围 | 戒 | ⿹戈廾 | 𢧌 | ⿹或壬 |
| U+2FFA | ⿺ | 左下角包围 | 超 | ⿺走召 | 𥘶 | ⿺礼分 |
| U+2FFB | ⿻ | 交叉结构 | 巫 | ⿻工从 | 𣏃 | ⿻木⿻コ一 |
| U+2FFC | ⿼ | 右侧包围 | 㕚 | ⿼叉丶 | 𬺹 | ⿼コ二 |
| U+2FFD | ⿽ | 右下角包围 | 氷 | ⿽水丶 | 斗 | ⿽⺀十 |
| U+2FFE | ⿾ | 水平翻转 | 卐 | ⿾卍 | 𣥄 | ⿾正 |
| U+2FFF | ⿿ | 旋转 | 𠕄 | ⿿凹 | 𠄔 | ⿿予 |
| U+303E | 〾 | 形似但不相等 | 㬵 (U+3B35) | 〾胶 (U+80F6) | 𫜵 | 〾爫 |
| U+31EF | ㇯ | 减去笔画 | 乒 | ㇯兵丶 | 𧰨 | ㇯豕一 |
如上表所示,U+2FF0到U+2FFF范围内的十六个特殊字符可以充当前缀运算符,组合其他字符或序列,用于动态组字。另有两个IDC描述符U+303E和U+31EF为后续补充的描述符。
- 为什么在上表中有两个字形相同的「胶」,一个是U+3B35,另一个是U+80F6?
一个月字旁,和月亮有关,「U+3B35 胶=⿰月交」,本义为日月之交道。
一个肉字旁,和身体有关,「U+80F6 胶=⿰肉交」,本义为胫骨。
其中一个还是「U+81A0 膠」的简化字。因为「膠」的本义是「用动物的皮或角熬出来的黏黏的东西」,所以这个「膠」也是肉字旁,它的简化字位于U+80F6。
- 如果所要表示的汉字的构字部件不止两个怎么办呢?
类似用 “- + 1 2 3”表示“1+2-3”,这种“前缀表达式”可以将十六种 IDC 组合成 IDS 。如“ ⿸厂⿱今止 ”相当于“ ⿸厂(⿱今止) ”,即先对「今」和「止」做上下结构的拼合,再对这个拼合部件与「厂」做左上方的半包围拼合。
更多组合示例: