
在跨越数千年的中华文明演进历程中,汗牛充栋的典籍构成了独特的文明基因库。这些文献遗产不仅系统记载着古代中国的治政方略与典章制度,更铭刻着华夏文明的哲学思想精粹与人文精神图谱,堪称解码中华文明连续性的核心密钥。在数字技术赋能下,我国通过体系化推进古籍再生性保护工程,已取得了显著进展,不仅重构了学术研究的范式路径,更在全球化语境中搭建起传统文化创新传播的数字桥梁,为激活文化遗产的当代生命力提供了技术解决方案。
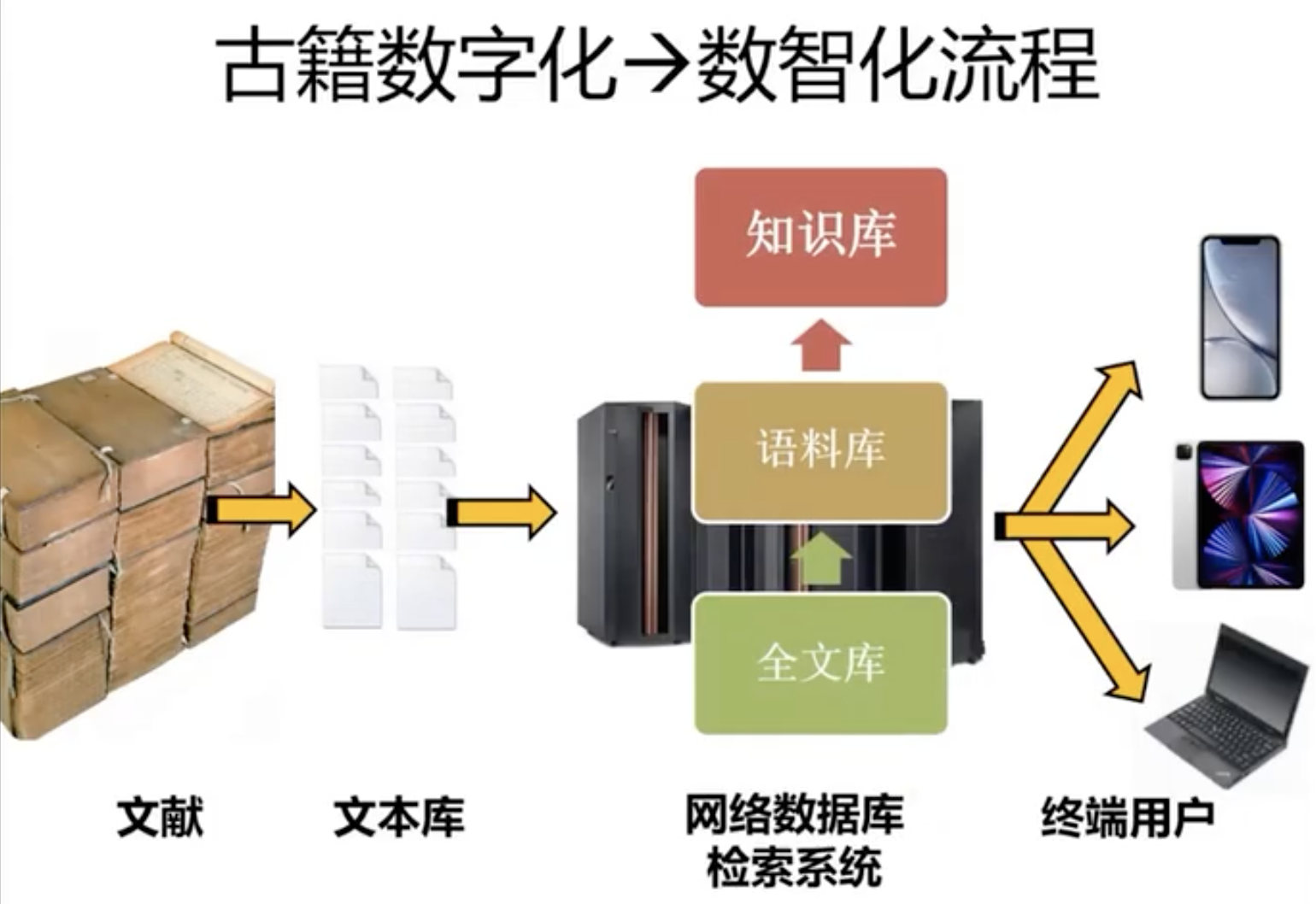
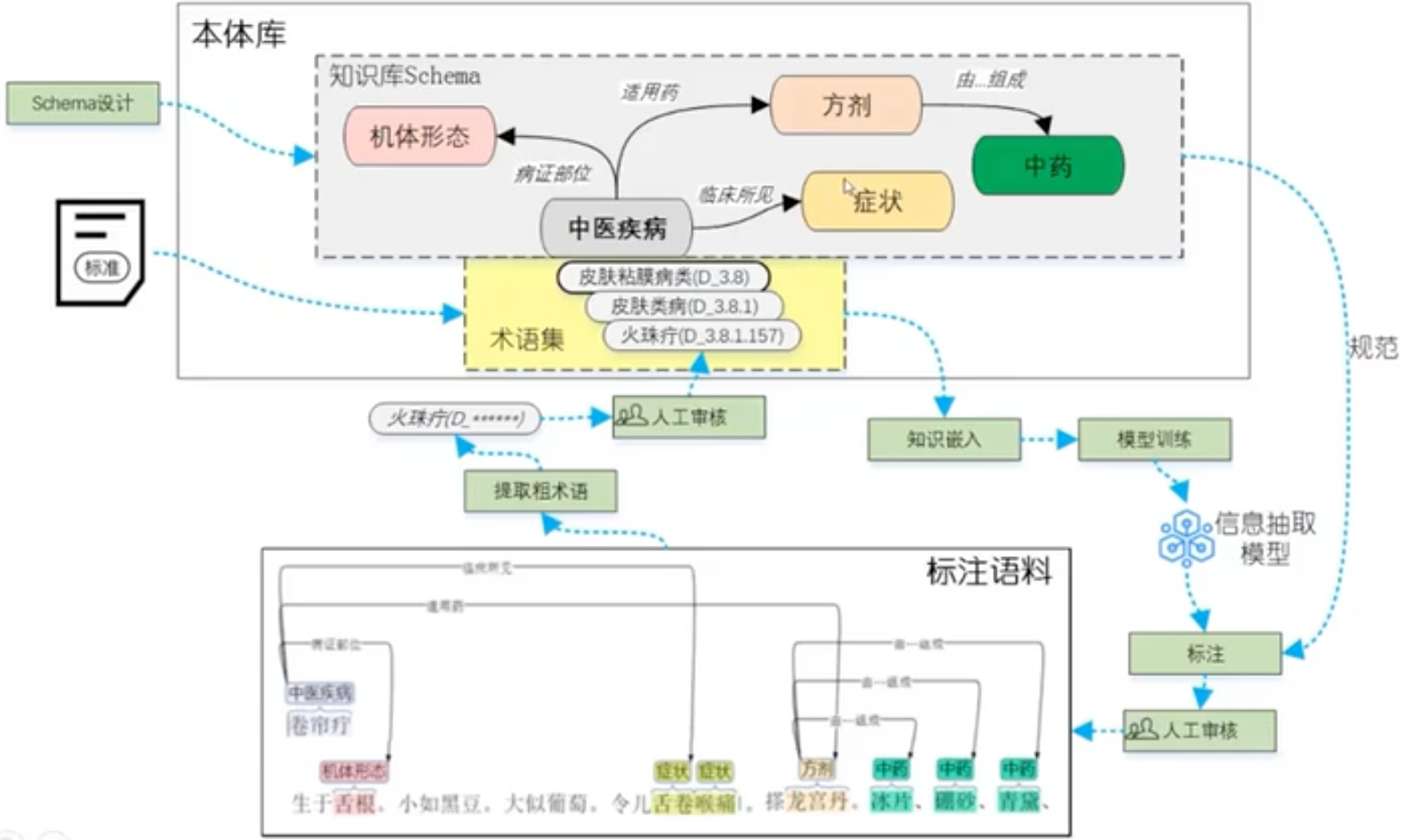
古籍数字化资源呈现出多维度的组织形态,根据知识加工层级可划分为五大类型:原版影像库、书目数据库、全文检索库、语料数据库及结构化知识库。这些资源构建出逐级递进的知识服务能力——基础层级的影像库侧重古籍原貌存真,中级层级的书目库和全文库实现书目/文本可检索,高级层级的语料库和知识库则致力于知识关联与语义挖掘。随着古籍资源结构化程度的不断提升,其服务能力也由单纯的文献获取向知识发现演进。
当前,越来越多的古籍原版影像库提供开放访问,“全球漢籍影像開放集成系統”通过整合全球汉籍影像资源,实现了古籍数字化资源的汇聚和共享,为学术研究提供了丰富的素材。
从古籍数字化资源的应用来看,除学术研究外,教学应用和文化普及构成另外两大核心需求。学术研究强调知识体系的系统性和学理深度,要求资源具备规范的引证溯源与多维关联;教学应用注重与教材知识点的精准映射,需构建适配不同学段的课程资源包;文化普及则追求传播效度,通过可视化叙事、交互体验等创新形式实现传统文化的现代转译。
在数字人文视域下,古籍「活」化呈现出多维度的技术进化特征:其核心范式由资源聚合效应、开源生态构建、动态生长机制与认知计算体系构成。通过知识图谱技术实现的聚合效应,使原本离散的典籍文献形成拓扑关联,构建起跨文献的知识星系;基于互联网协议栈搭建的开源生态,不仅实现文献的泛在化访问,更催生出众包校勘、协同标注等新型学术生产模式;依托元数据框架的动态生长机制,通过智能采集系统持续整合新出文献与民间收藏,形成具有自我进化能力的数字记忆体;而融合深度学习的认知计算体系,则突破传统检索局限,实现从字形匹配到语义推理的跃迁。特别是古文大语言模型的应用,通过预训练数十亿字级的古籍语料,不仅能完成自动标点、异体字转换等基础任务,更能深度解析文言语法结构,生成符合古代语境的注释译文,甚至可模拟历史人物的思维范式进行跨时代对话。这种技术驱动的范式革命,正在重塑从知识生产到文化传播的全链条价值网络。
| 数据库类型 | 构建基础 | 技术支撑 | 应用场景 |
| 原版影像库 | 影印古籍图片 | 图片扫描 | 版本考据、阅读 |
| 书目数据库 | 字符串 | 普查登记 | 阅读、文本检索 |
| 全文检索库 | 字符串 | 光学字符识别 | 阅读、文本检索 |
| 语料数据库 | 采用语言学方法加工的语料 | 分词、词性标注、专名识别 | 科研、分级教材编写等 |
| 结构化知识库 | 结构化数据 | 人工智能、大数据 | 科研、基础教育、国学普及、对外交流等 |
古籍数字化的过程是一项集文献数字化、分类检索、整理校勘于一体的综合性工程,不仅是对古代文献的守护与延续,也是对传统文化资源的深度挖掘与创新应用。如国家图书馆(国家古籍保护中心)“中华古籍资源库”,整合了国内外多家机构的古籍资源,涵盖甲骨、敦煌文献、碑帖拓片、地方志、家谱等类型。
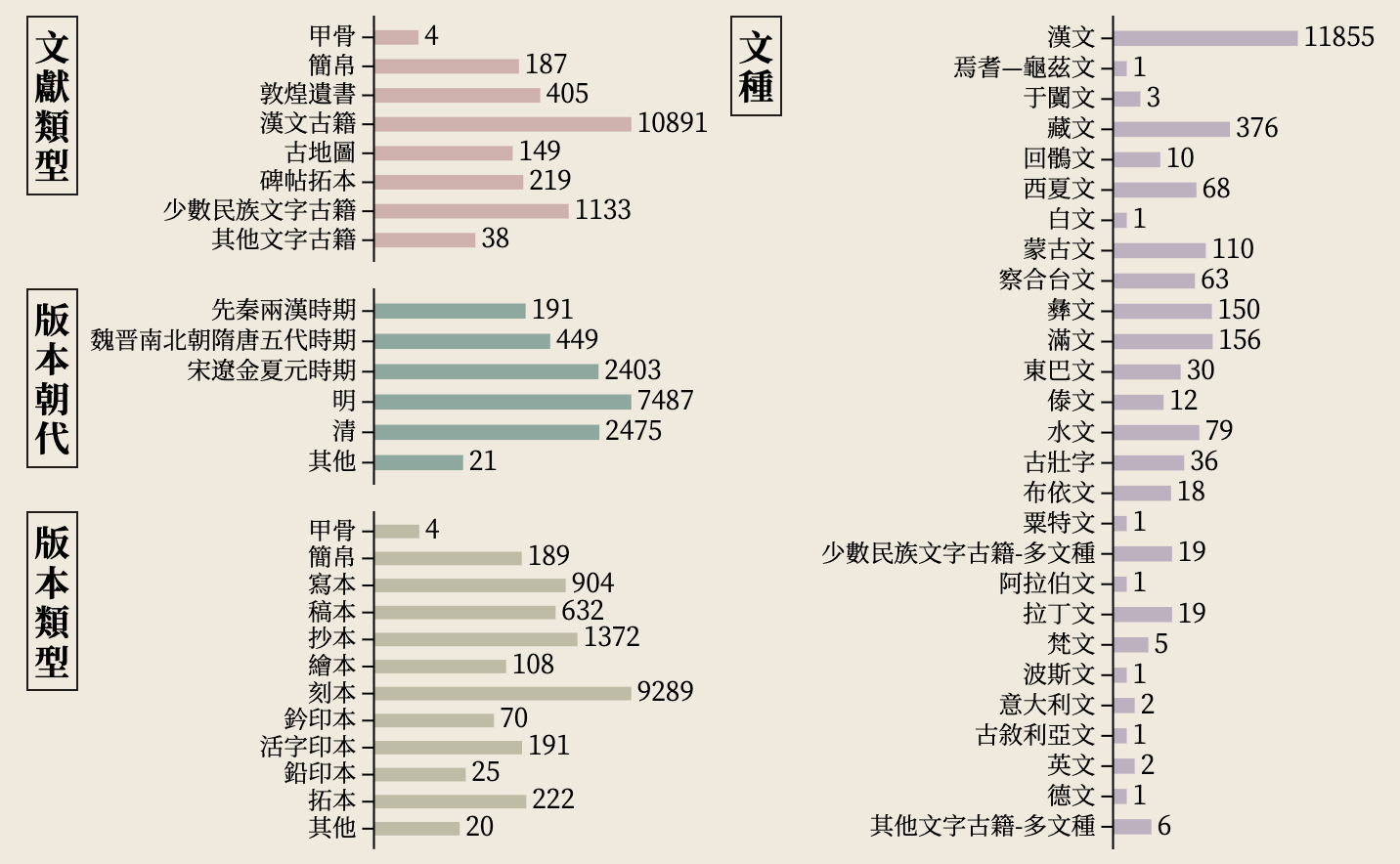
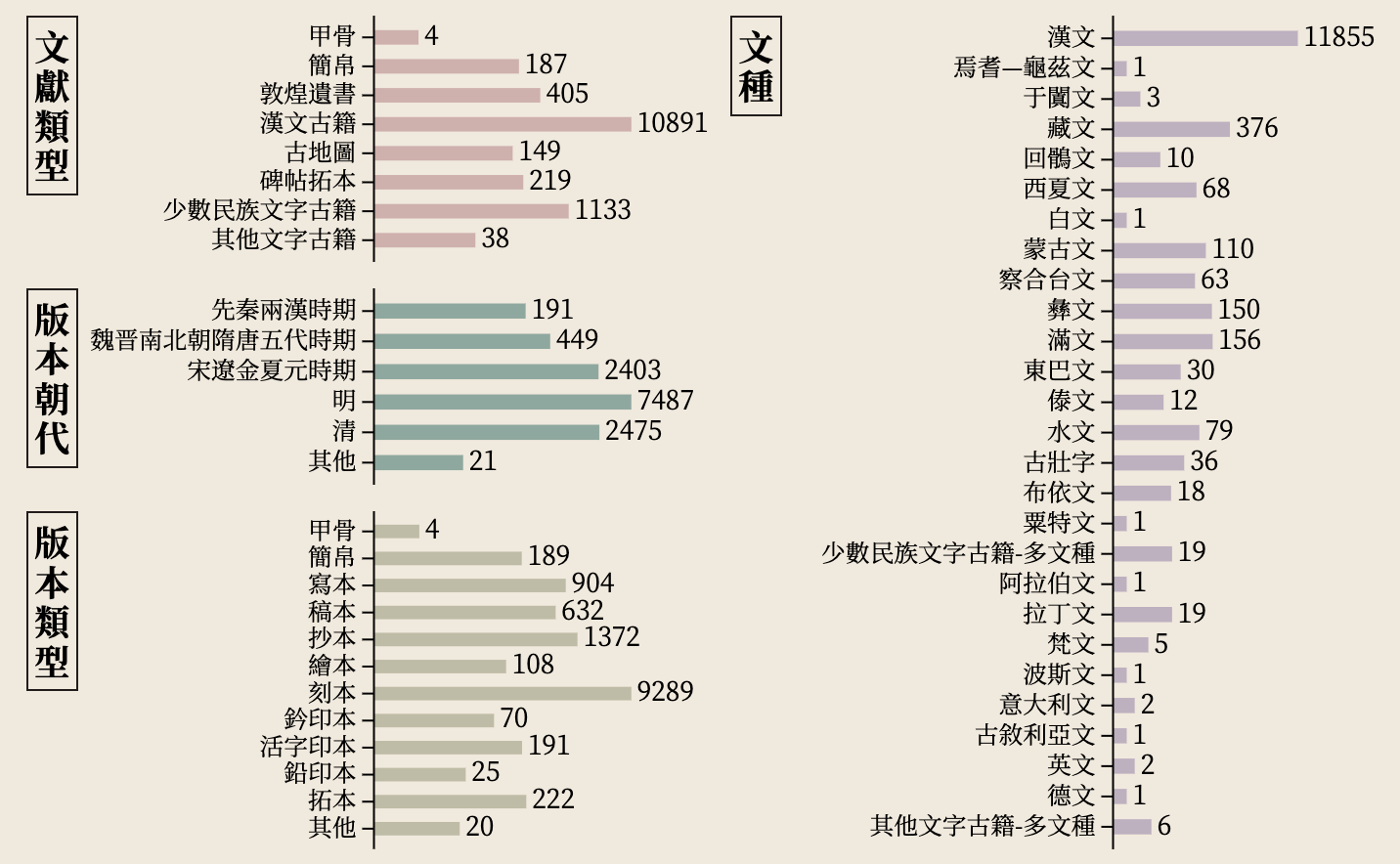
截至2020年底,国务院公布已公布六批《国家珍贵古籍名录》,全国485家机构/个人收藏的13026部古籍入选,囊括先秦两汉至明清时期的汉文古籍、少数民族文字古籍和其他文字古籍。其中,汉文文献11855部(含甲骨4种、简帛187种、敦煌遗书405件、碑帖拓本219件、古地图149件、汉文古籍10891部),少数民族文字古籍1133部,其他文字古籍38部。
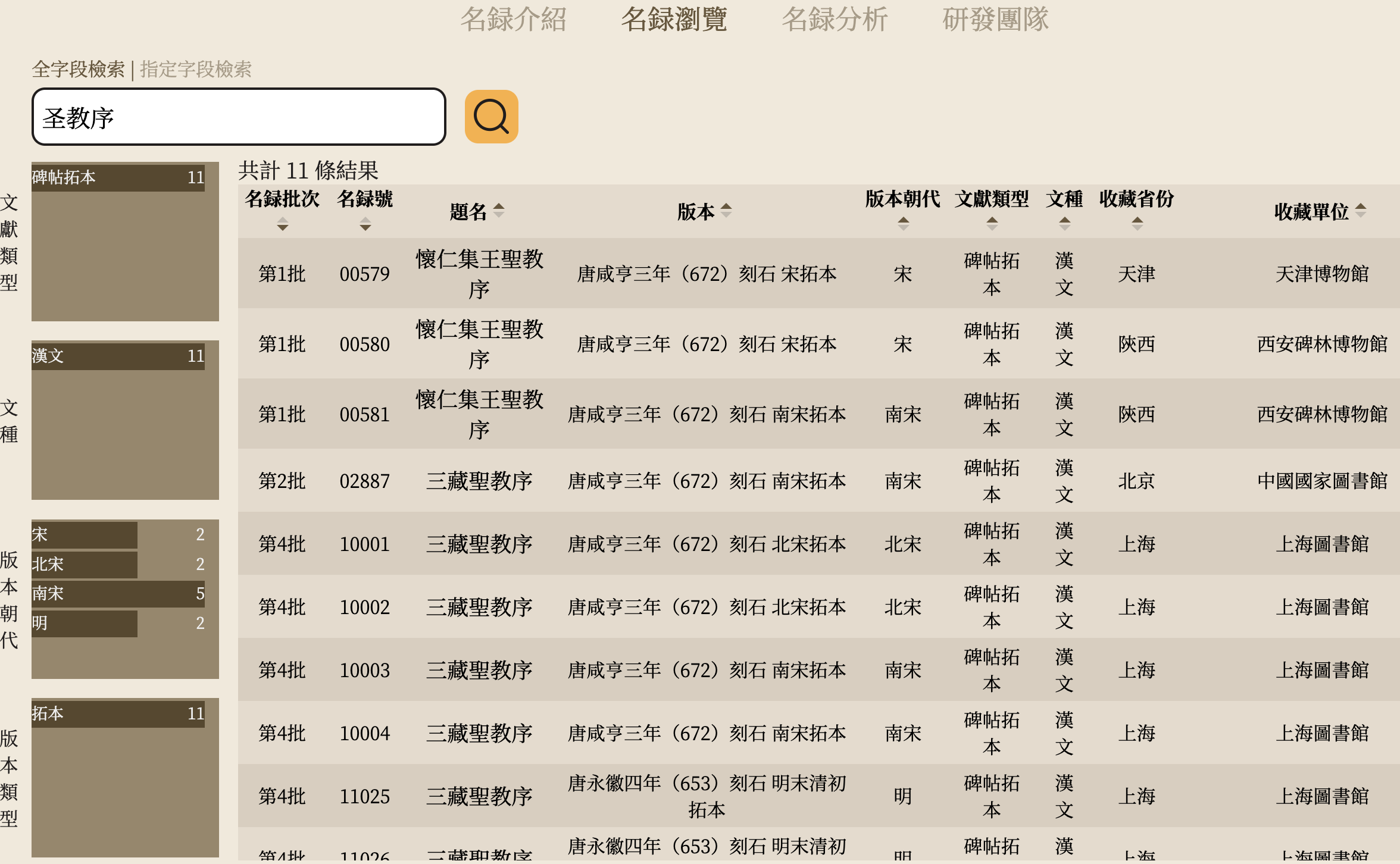
2021年,国家图书馆(国家古籍保护中心)和北京大学数字人文研究中心联合设计开发了“《国家珍贵古籍名录》知识库”,结合多字段检索与多维度导航功能,为用户提供了解古籍的入口与工具。两种查阅名录收录古籍的方式,一方面支持用户精确查询,另一方面便于用户从文献类型、文种、版本朝代、版本类型四个维度联合筛选,逐步探索名录收录古籍的丰富内涵。名录分析页面充分利用关联语义技术,呈现名录中隐含的人物关系与书目关系,结合统计功能帮助更多用户进一步深入探索。
国内在古籍数字化领域较为知名企业的产品还有:古联(北京)数字传媒科技有限公司的“中华经典古籍库(籍合网)”、北京爱如生数字化技术研究中心的“中国基本古籍库”、北京抖音信息服务有限公司的“识典古籍(北京大学-字节跳动数字人文开放实验室)”等。
古籍是如何实现数字化的?
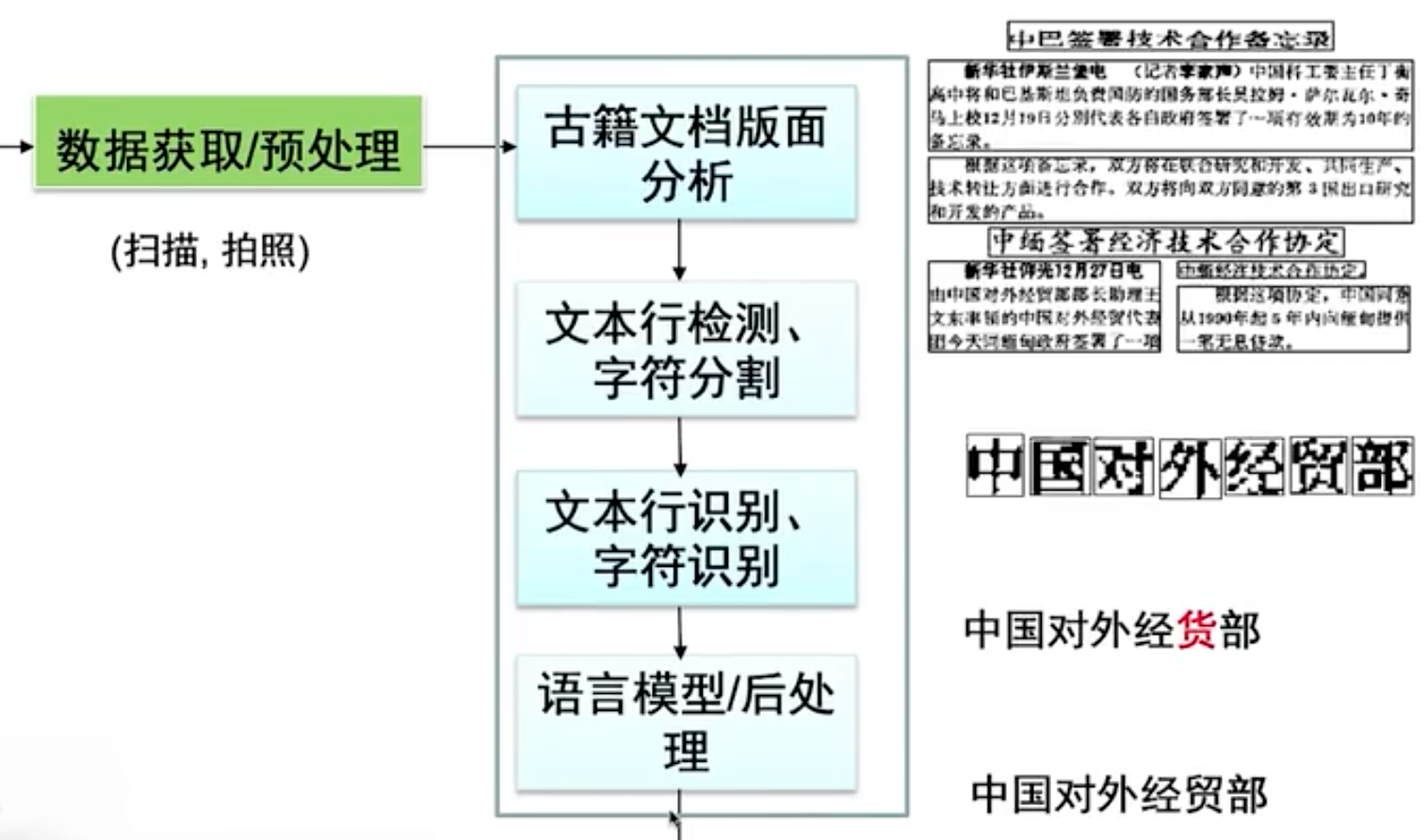
古籍数字化技术体系通常由三个核心环节构成:首先采用高精度非接触式扫描设备进行原典影像采集,确保古籍实体零损伤的同时获取高保真图像数据;其次运用智能处理技术链对图像内容实施深度解析,该技术链以光学字符识别(OCR)为基础支撑,结合自然语言处理(NLP)与知识图谱(KG)构建复合型技术框架;最终通过结构化元数据著录形成古籍文本数据库和多维古籍知识库。
相较于传统古籍文本数据库存在的显著局限——原始版式特征丢失导致版面美学价值衰减、异体字通假现象引发的检索盲区、特殊字符集支持不足造成的显示异常等问题,现代智能处理技术展现出突破性优势:通过版面分析算法可精准还原古籍的版框界栏、行款格式等物质形态特征;基于深度学习的文字识别模型能有效处理异体字、俗写字等复杂字形;而NLP与KG技术的融合应用,更衍生出自动句读标点、跨版本全文检索、命名实体智能标注、语义关系网络构建等知识服务功能,推动古籍文献从数字化存储向知识化服务转型升级。
1、文字识别阶段
在OCR处理流程中,首先执行版面元素解构:通过基于连通域分析的图像分割算法,完成单字级字形切分;继而采用卷积循环神经网络(CRNN)模型对离散字形实施特征提取与分类识别;最终通过坐标定位与行序重建算法,实现文本流方向解析与阅读逻辑还原。当前行业标准OCR准确率均值为93%-94%(以《四库全书》样本集为基准),而"识典古籍"项目通过构建百万级古籍异体字训练集与迁移学习优化策略,将综合准确率提升至96%-97%,显著突破复杂版式下的识别瓶颈。

2、语义解析与自动句读
基于NLP技术的自动句读系统,采用双向长短期记忆网络(Bi-LSTM)与条件随机场(CRF)组成的序列标注模型,对连续字符流进行语义边界预测。技术实现路径包含:①将OCR输出的UTF-8编码文本向量化;②通过注意力机制捕捉上下文依存关系;③结合古籍语法规则库进行标点概率计算。以《论语》首章处理为例,输入序列"学而时习之不亦说乎"经模型解析后,输出符合现代阅读习惯的"学而时习之,不亦说乎?",其句读准确率可达98%以上(基于CBLEU评测标准)。
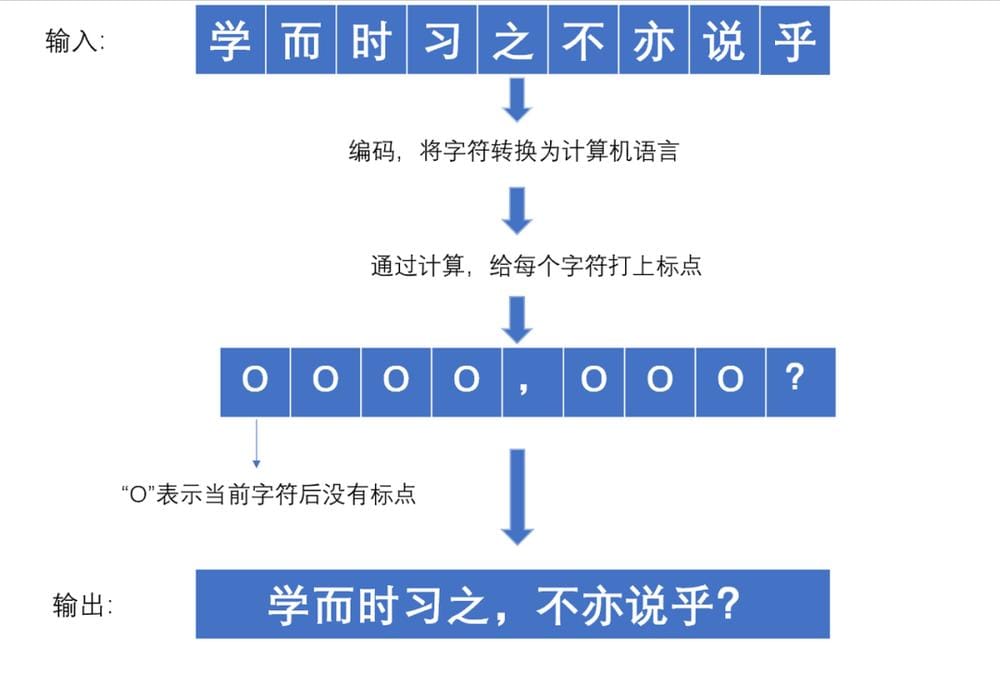
3、命名实体识别
基于预训练大语言模型和含有标注实体的古籍语料库,通过多任务学习同步预测字词边界与实体类别,精准识别五大核心实体类型:
- 人名实体:涵盖字号、别称、谥号等异名映射
- 地理实体:包含历史沿革地名与坐标时空绑定
- 典籍实体:实现跨版本著作关联与引文溯源
- 时间实体:支持干支纪年与帝王年号智能转换
- 职官实体:解析历代官僚体系结构与职能演变
当前研究表明在明刻本样本中的实体识别F1值可达92.3%。

文以载道,源远流长,古籍穿越历史的长河,带着古人的智慧向我们走来。我们期待与更多同学一起,助力古籍传承,让古籍真正活起来,传下去。
古汉语语料库/知识库
不同于印欧语系自带分词,古汉语的特点是一字一词为主,多字词比如天下、诸侯、大夫、君子、社稷等需要做分词的标注。古籍数字化还需要完成基本的分词、断句、标点等工作。
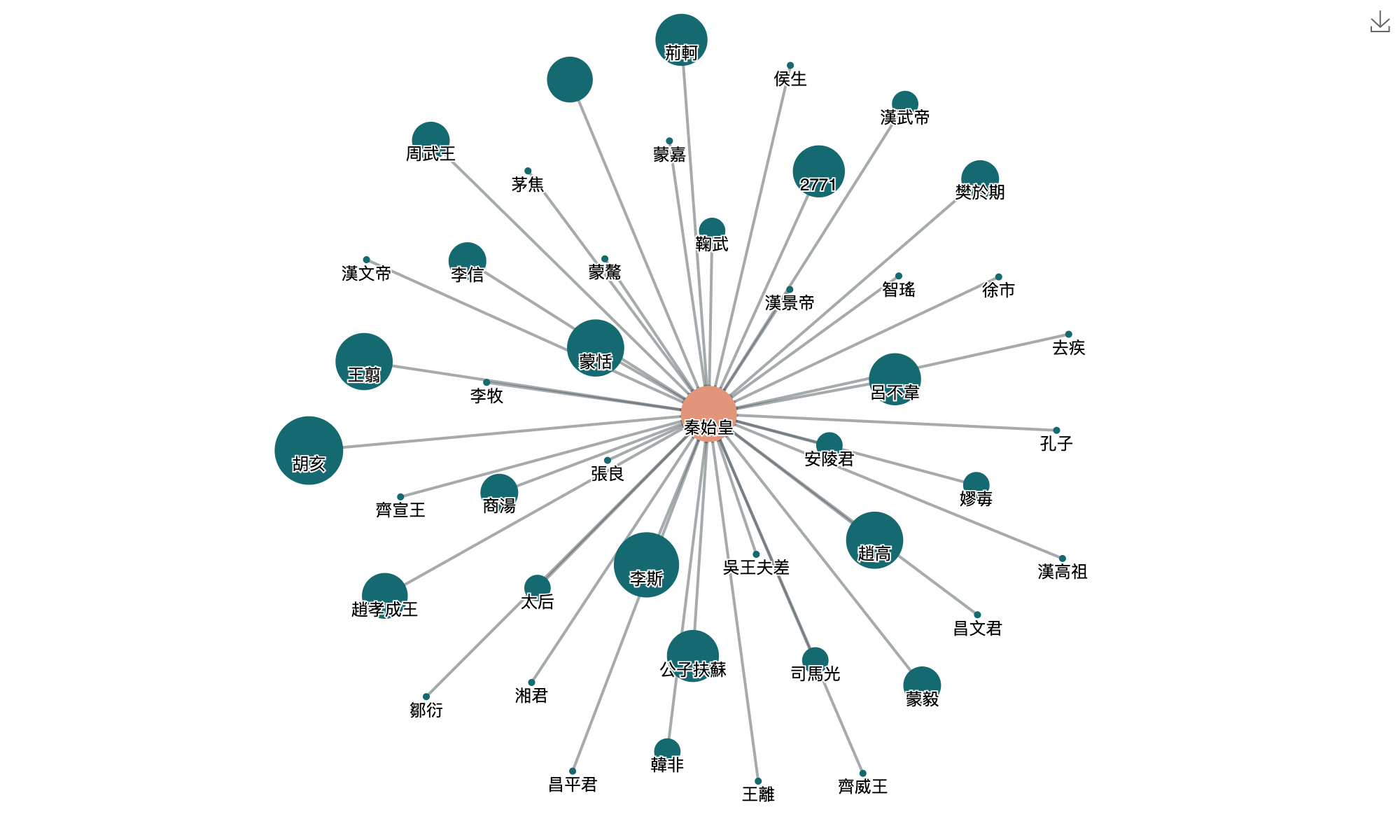
从语言学的角度,语料库包含词性标注和词义标注,方可支持词汇级的检索。进一步需要知识性的标注(知识库),特别是对于人物、地点、年代、组织、事件、概念和术语的标注,从而应用于文献学、历史学、文化传播和国学教育等领域。比如,对于秦始皇(始皇帝、始皇、秦王政、政、吕政、赵政、公子政)来说,这些词指代同一个人物概念,如果语料库仅仅支持字符串的检索是远远不够的。这就需要针对人名、地名、事件和年代做专名/命名实体(Named Entity)的标注。
举例:LDC语料库(Linguistic Data Consortium),收录语料库(corpora)900余个,涉及语言包括英语、汉语、阿拉伯语、波斯语、土耳其语、格鲁吉亚语、普什图语等。每年增加30-36个新资源。 LDC语言数据联盟是由大学、图书馆、公司和政府研究实验室组成的语言公开联盟,隶属于宾夕法尼亚大学文理学院(School of Arts and Sciences),成立于1992年,主要负责科研语言资源的收集、保存与管理分发。
举例:古汉语标记语料库(Academia Sinica Ancient Chinese Corpus) ,建構始於一九九0年,創始者為黃居仁(台湾語言所研究員)、譚樸森(英國倫敦大學亞非學院教授)、陳克健(台湾資訊所研究員)、魏培泉(台湾語言所研究員)等,最初的經費來源為蔣經國基金會及中央研究院歷史語言研究所,目標是蒐集上古漢語的素語料。素語料庫的構建自此未曾停歇,語料也由上古漢語擴充到中古漢語和近代漢語。
举例:BCC汉语语料库(北京语言大学),总字数约 95 亿字,包括:报刊(20 亿)、文学(30 亿)、综合(19 亿)、古汉语(20 亿)和对话(6 亿,来自微博和影视字幕)等多领域语料,是可以全面反映当今社会语言生活的大规模语料库。
举例:古文现代文翻译平行语料库,基本涵盖了大部分经典古籍著作。经过脚本进行分句、对齐,处理成了句子级别对齐的双语(平行)数据,共计 972467 句。可基于古文预训练大模型,如荀子基座大模型,进行LoRA微调训练,实现现代文转古文大模型。
其他开源工具和数据:
- OpenCC: 简繁转换工具
- zhconv: 简繁转换工具 (注意需使用zh-hans选项,只转换单字,避免转换地区词)
- 甲言Jiayan: 古汉语处理的NLP工具包,古文分词,词性标注,断句,标点等工具
- "吾与点"古籍自动整理平台:平台包含自动标点/自动句读,自动分词,专名识别,关系抽取等功能
- “AI太炎”古诗文断句:支持自动标点/自动句读、书名/专名识别
- daizhigev20: 殆知阁古代文献数据库
- chinese-poetry: 最全中文诗歌古典文集数据库
- LT4HALA:古文信息处理评测基准
- CCLUE:古文自然语言理解测评基准,包括代表性任务对应的数据集、基准模型、评测代码
语料库/知识库的文本标注成本巨大,需要运用自然语言理解领域的实体挖掘(命名实体识别NER,如SiKuBert+BiLSTM+CRF模型)、属性抽取、关系抽取等技术完成自动标注,再结合人工的校对。
古汉语知识库案例:

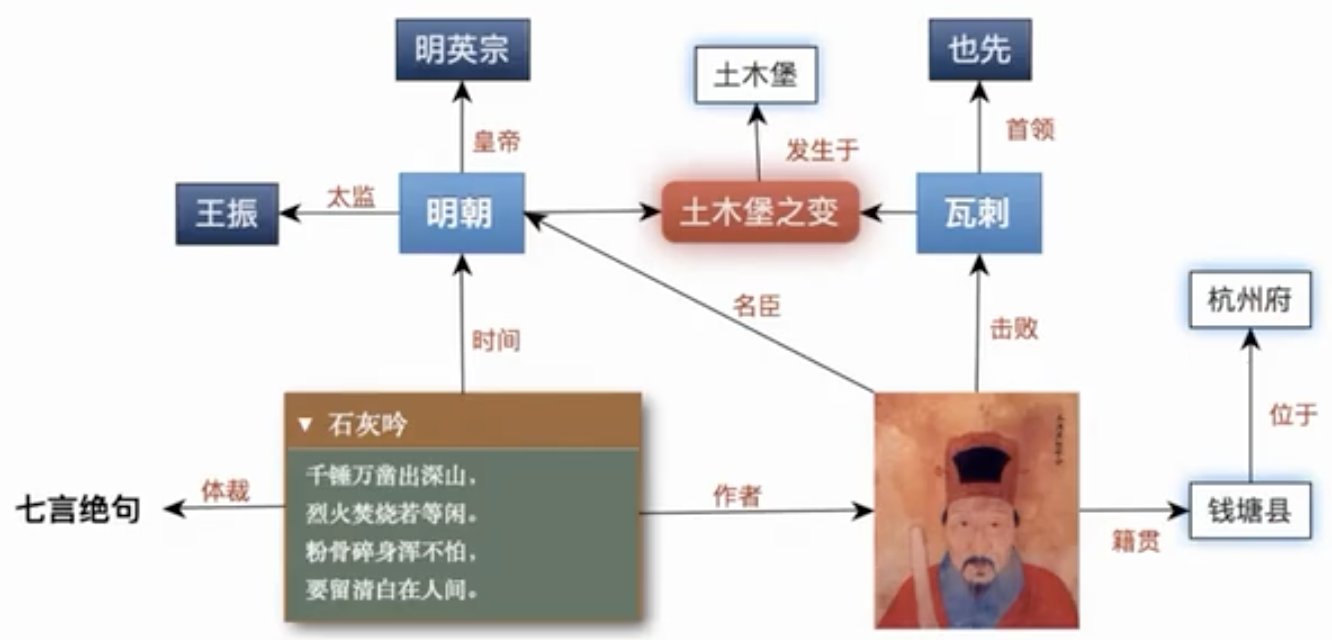
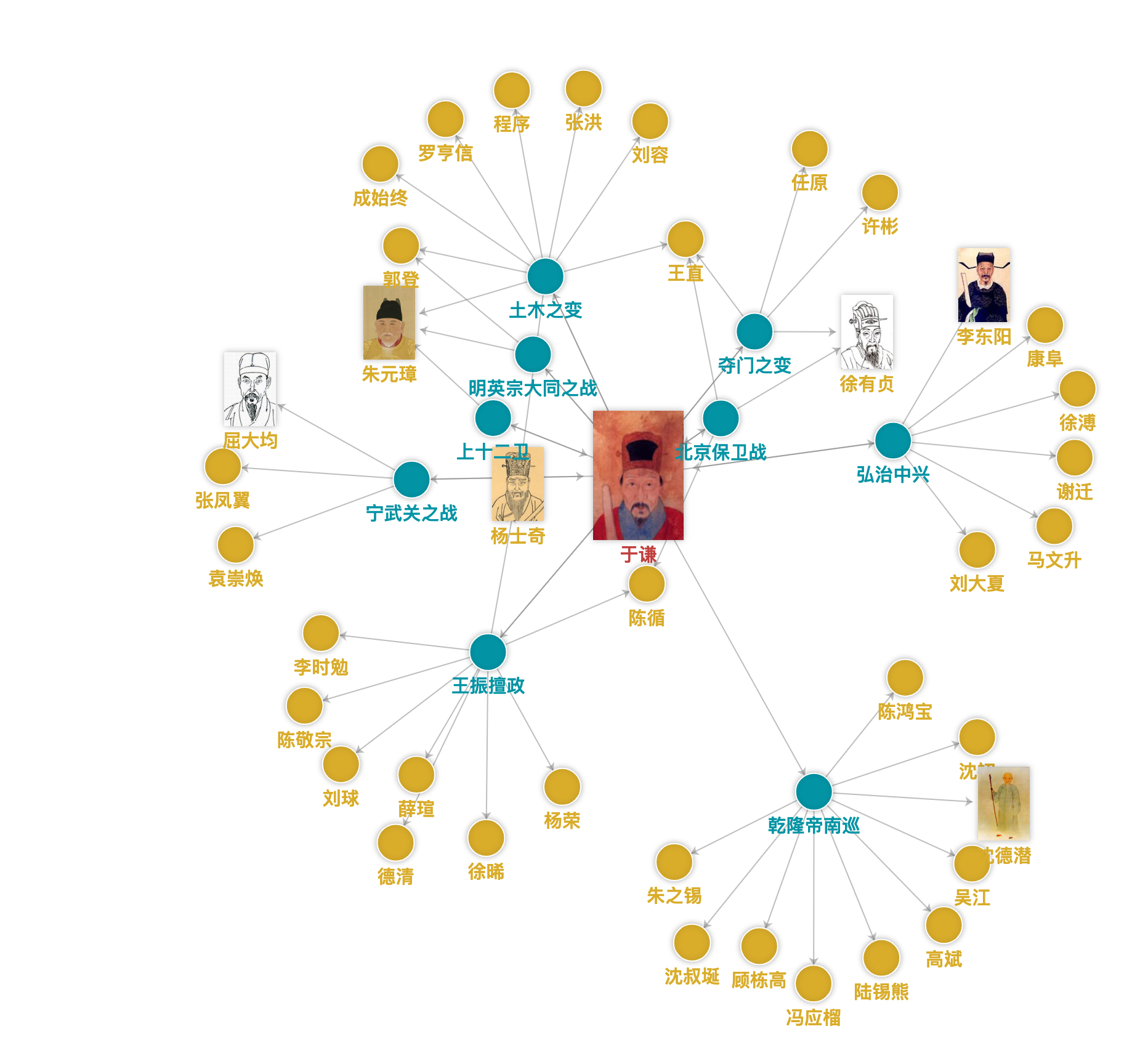
基于文本标注,结合计算语言学和可视化技术,可以进一步挖掘人物社交关系(同一句中人物的同现网络)、人物旅行距离、人物地点的年代分布、地名时间热力图、人物时空地图、历史事件关系(如安史之乱背景相关的诗词)、意向情感关系(诗词中的名词性意象与表达的情感)等等。
举例:中华诗词图谱(中科院软件所)诗词的立体化展示和理解
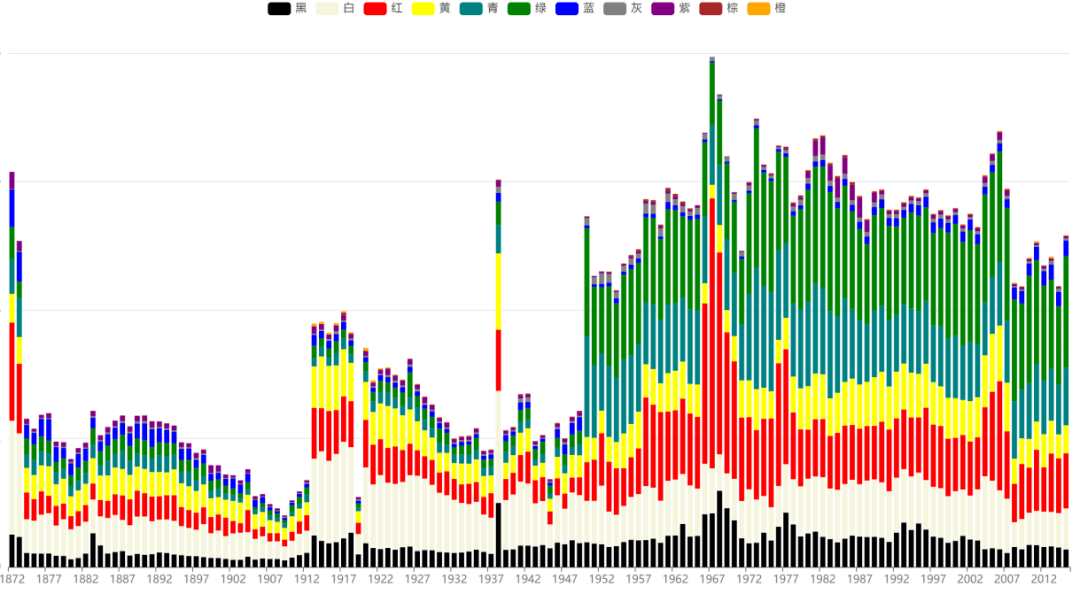
现存问题:
- 更精准、更全面的语料库构建, 文体演变所带来的分词问题仍旧是一个存在争议的难点;
- 多模态数据融合,包含文献文本、实物藏品、图像、语音等多模态数据,例如古籍的实物/实地图像、拓本图像和释文。
- 大规模的自动化分析与标准化评测;
- 更好的人机交互/跨平台的应用。
古文大模型
古文自然语言处理模型合集
古文预训练语言模型是处理各种古文任务的基础模型,需要结合各种下游任务数据微调,才能发挥最大作用。这里收集了所有互联网上公开的古文预训练语言模型:
| 名称 | 简/繁 | 下载链接 | 备注 |
|---|---|---|---|
| guwenbert-base | 简 | Hugging Face | 基于殆知阁语料和中文模型训练 |
| guwenbert-large | 简 | Hugging Face | |
| guwenbert-fs-base | 简 | One Drive | 基于殆知阁语料从头训练 |
| roberta-classical-chinese-base-char | 简繁 | Hugging Face | 基于guwenbert训练,扩展了繁体词表 |
| roberta-classical-chinese-large-char | 简繁 | Hugging Face | |
| sikubert | 繁 | Hugging Face | 基于四库全书语料和中文模型训练 |
| sikuroberta | 繁 | Hugging Face | |
| sikuGPT2 | 繁 | Hugging Face | |
| GujiRoBERTa_jian_fan | 繁简 | Hugging Face |
研究背景及意义
几千年辉煌的华夏文明,留下了海量的古籍文献资料。这些文献中蕴含着丰富的历史、文学、语言、文化知识,在大数据、大模型、人工智能技术快速发展的时代,如何利用新技术,挖掘和活化利用古籍,是当前研究的热点。
为响应古籍文化遗产保护、古籍数字化与推广应用的国家战略需求,传承中华优秀传统文化,挖掘利用古籍文献中蕴含的丰富知识,古籍透彻数字化工作势在必行。
由于古籍文档图像的版式复杂,不同朝代、不同地区的刻字书写风格差异大,古籍文字图像存在缺失、污渍、笔墨污染、模糊、印章噪声干扰、生僻字异体字繁多等技术挑战,古籍文档图像的智能修复与识别依然是一个极具挑战的技术难题。该领域包含高精度古籍版式分析、文本检测、文本行识别、端到端古籍识别、图像修复等技术。

任务描述
任务:古籍文档图像修复与识别
输入: 篇幅级别的古籍文档图片
输出: 利用文档图像物理及逻辑版面结构分析、文本检测、文字识别、文字阅读顺序理解、图像修复和图像理解等技术输出结构化的文本行坐标以及识别内容,其中各个文本的检测结果与识别内容按阅读顺序进行排列输出。模型仅输出正文的检测识别结果。忽略如版心、卷号等非结构化的内容。
评估方法
文本识别性能指标:
- 首先使用IoU计算预测文本框和标签文本框的匹配情况,选出和标签文本框IoU最大且最大IoU>0.5的预测框为匹配的文本序列串;
- 接着对匹配的文本串计算归一化的编辑距离(NED)。
- 考虑到误检的惩罚,对于没有与标签文本框匹配的检测文本框,会与空序列计算编辑距离。Norm1为最终的指标结果。
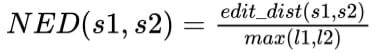
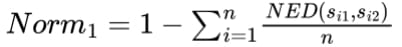
其中,s1和s2为匹配的文本序列串,l1和l2分别为各自的文本行长度,n为匹配对的文本行个数。
阅读顺序识别性能指标:
为了提升阅读顺序识别的性能,往往需要在返回文本识别结果时对文本框进行重新排序,性能指标借鉴Average Relative Distance(ARD)。
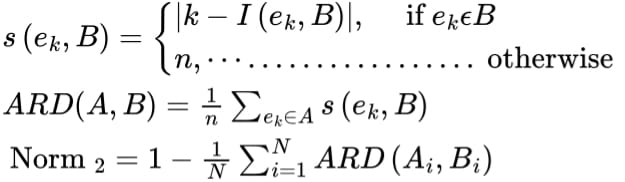
其中,A表示目标序列,B表示模型的生成序列:
- ek表示序列A中的第k个文本行。
- I(ek, B)表示当A中第k个元素ek在生成序列B中时,返回此时在B中的索引;
- ARD(A, B)返回当前图片的阅读顺序检测指标;
- Norm2为最终的指标结果。
1.古籍文档图像识别比赛数据集
粤港澳大湾区(黄埔)国际算法算例大赛提供了带标注的训练集和验证集,各包括了1000幅古籍文档图像(共2000张图像),数据选自四库全书、历代古籍善本、乾隆大藏经等多种古籍数据。
数据标注格式
每幅图像文本行文字及内容根据文本行阅读顺序进行标注,包含在一个单独的json文件。标注格式如下所示:
{
“image_name_1”, [{“points”: x1, y1, x2, y2, …, xn, yn, “transcription”: text},
{“points”: x1, y1, x2, y2, …, xn, yn, “transcription”: text},
…],
“image_name_2”, [{“points”: x1, y1, x2, y2, …, xn, yn, “transcription”: text},
{“points”: x1, y1, x2, y2, …, xn, yn, “transcription”: text},
…],
……
}
- x1, y1, x2, y2, …, xn, yn代表文本框的各个点。
- 对于四边形文本,n=4;数据集中存在少量不规则文本,对于这类标注,n=16(两条长边各8个点)。
- Text代表每个文本行的内容,模糊无法识别的字均标注为#。
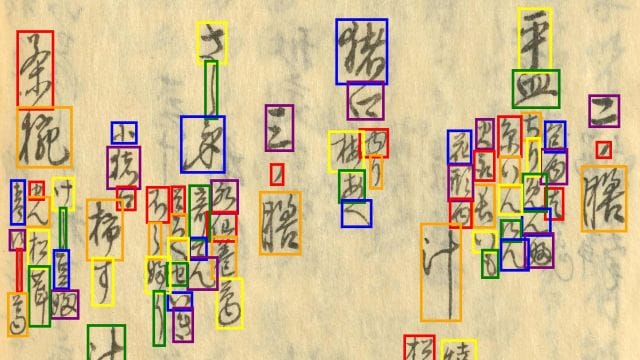
- 其中文本行的检测与识别标签按照正确的阅读顺序给出。端到端识别内容按照阅读顺序进行标注,仅考虑文档的正文内容,忽略如版心、卷号等边框外的内容。
- 阅读顺序的编排如下图所示。

2.大藏经数据集MTHv2
华南理工大学提供大藏经MTHv2数据集,包含2200张文档图像。

MTHv2包含三种类型的标注:
第一类是行级注释,包括文本行位置及其文本内容,并按阅读顺序保存。
第二类是字符级注释,包括类别和检测框坐标。
第三类是边界线,由线段的起点和终点表示。
参考方法:
单字检测:https://github.com/Tverous/HRCenterNet,https://arxiv.org/abs/2012.05739
布局分析与字符识别:Joint Layout Analysis, Character Detection and Recognition for Historical Document Digitization
3.上海图书馆开放数据竞赛
上图开放数据竞赛为参赛者提供更加丰富和海量的历史人文数据。


4.日本草书体古籍
截至2019年11月,包含44本经典书籍(主要是江户时代的书籍和手稿)的6,151张图像,从中剪切出4,328个字符类型,共包含1,086,326张字形图像。并统计了各字符的出现频率。其中,Kuzushiji-Kanji数据集中包含了很多中文草书的字形,KanjiVG是含笔顺信息的矢量字库。

Kuzushiji草书体自公元 8 世纪开始在日本使用,已有一千多年的历史。如今,日本保存了超过300万本草书体书籍,涉及文学、科学、数学和烹饪等各种主题。然而,随着现代印刷技术的普及,以及1900 年的日本教科书标准化,将草书体从学校课程中移除,如今大多数日本人已无法阅读 120 年以前编写的书籍。
自公元 8 世纪汉字传入日本以来,官方记录中一直使用Kanji(日语中的汉字)书写日语。然而,从公元 9 世纪末开始,日本人开始添加自己的字符集:Hiragana(平假名)和Katakana(片假名),它们源自汉字的不同简化方式。单个平假名和片假名字符不包含独立的语义含义,而是带有语音信息(类似英文字母表中的字母)。
在古代Kuzushiji草书体文献中,Kanji、Hiragana和Katakana都有使用。同时,因文献类型不同所常有的字符类型也有所不同。例如,故事书大多用Hiragana平假名书写,而正式记录则主要用Kanji汉字书写。
Kuzushiji识别的难点
字符种类繁多: Kuzushiji 数据集中的字符总数超过 4300 个,频率分布非常长尾,很大一部分字符(具有非常特定含义的汉字)可能只在某一本书中出现一两次。因此,数据集非常不平衡。
Hentaigana变假名:古典平假名或变假名(字符变体)的一个特点是,许多字符在现代日语中只能以一种方式书写,但在 Kuzushiji 中却可以以多种不同的方式书写。例如,下图展示了平假名Ha (は) 的多种不同书写方式。

字符之间的相似性: Kuzushiji 中的一些字符看起来非常相似,如果不考虑上下文,很难判断它们是什么字符。例如,下图中的红色圆圈显示了 3 种类型的字符:Ku (く)、重复标记和Te (て)。

字符之间的连接和重叠: Kuzushiji 是用草书书写的,因此在许多情况下,字符是连接或重叠的,这会使文本识别任务变得困难。在下图中,不同颜色的边界框显示出字符的重叠(框的颜色是为了可视化,不包含任何特定含义)。

复杂多变的排版布局: 雕版印刷和手写稿件的文档布局自由度很高,Kuzushiji 字符的排版布局(虽然通常排列成列)并不遵循单一的简单规则。因此,如下图所示,准确的识读出文本的序列并不那么容易。
GitHub: Repository for Kuzushiji_MNIST, Kuzushiji49, and Kuzushiji_Kanji
Kaggle 竞赛:Kuzushiji 字符识别
KuroNet自动识别服务:结合IIIF的方式值得借鉴(细节)
Kuzushiji图像生成:根据输入的文本,生成草书体图片。
5.水族水书古籍
大英图书馆的濒危档案计划 (EAP)曾资助两个项目(EAP143 和 EAP460),旨在将 16 世纪至 1990 年代的水族水书文献数字化,这些文献保存在贵州省荔波县档案馆和私人藏家中。EAP网站上可免费访问到这些资源,在IIIF-Viewer中浏览 。

随着古籍数字化技术的飞速发展,智能分析与识别技术在少数民族古籍文献领域的应用日益受到重视。尽管如此,少数民族文献如水族水书,因其图文混杂、排版多样化,以及自然和人为因素引发的图像退化和噪声问题,给文档的精确分析与识别带来了重大挑战。

本团队与华东师范大学中国文字研究与应用中心(国家人文社会科学重点研究基地)开展跨学科合作研究,已搭建水族水书数据库和智能识别系统。目前,团队针对低资源条件下的少数民族文档识别的共性科学问题,围绕水书文献,正在开展跨模态视觉语言理解与跨语言迁移学习模型的相关研究。